A Merge Queue on Steroids


In every engineering team, developers want to see their "ready to merge" work landing as soon as possible into their source code repository. Nobody wants to wait, and this directly impacts the velocity of the team.
The worst part of the merging process would be to have to revert a bad merge because it broke your main branch. Since you know better, you've set up your merge queue with Mergify. Great! 😉
If you are not yet familiar with what problems a merge queue solves, you can first take a look at this previous blog post.
Queue Configuration
Your queue configuration could be anything, but for the sake of this blog post, we're going to consider a pretty simple configuration. Let's say your configuration looks like this:
queue_rules:
- name: default
conditions:
- check-success=compile-and-test
pull_request_rules:
- name: merge using the merge queue
conditions:
- base=main
- "#approved-reviews-by>=2"
- check-success=compile-and-test
actions:
queue:
name: defaultGreat configuration. With that, all your fellow engineers are cheerful: no more manual rebase/update headache. Once ready to be merged, their pull request gets queued, updated with the latest tip from the base branch, tested, merged, and the main branch stays green forever. Yay.
They can spend their time doing something else.

The Merge Queue Throughput 🧐
Now that your queue is getting full of pull requests, you can even predict the time it takes to get code merged once it enters the merge queue.
It's simple: if your CI takes 30 minutes to validate a change and your queue has 10 pull requests on average:
- You will be merging 2 pull requests per hour. That's your maximum throughput;
- Your minimum latency is 30 minutes;
- Your average latency is 2.5 hours;
- Your maximum latency is 5 hours.
Now, the question is: can we do better?
Increasing your merge throughput 💨
The default merge queue configuration is delicate with the CI budget as Mergify checks each pull request, one per one.
Never mind the pull request passing or failing; Mergify will run only 1 CI suite at a time to not burn too much CI time on your behalf.
However, if you're willing to consume more CI budget to increase your merge throughput, you can do this using the speculative check feature.
Here's an example configuration:
queue_rules:
- name: default
conditions:
- check-success=compile-and-test
speculative_checks: 3
pull_request_rules:
- name: merge using the merge queue
conditions:
- base=main
- "#approved-reviews-by>=2"
- check-success=compile-and-test
actions:
queue:
name: defaultTo enable speculative checks, you just need to set speculative_checks: 3 in the configuration — or to any other value that suits you.
Now instead of checking the mergeability of pull requests #1, then #2, and then #3, Mergify checks in parallel #1, #1 + #2, #1 + #2 + #3. This triggers 3 CI runs in parallel and prevents Mergify from waiting for #1 and #2 to be merged to check if #1 + #2 + #3 is mergeable.
It's doing all of that at the same time.
Now, if we keep our average of 10 pull requests being in the queue, this means we now have a merge queue with:
- 6 pull requests per hour of maximum throughput;
- 30 minutes minimum latency;
- 1-hour average latency;
- 2 hours maximum latency.
Way better: we divided our average latency by 2.5 and multiplied our throughput by 3! But wait… what's the catch here?
The Failure Case ❌
The trade-off is the following: while the throughput is increased and the latency is reduced, the number of running jobs might be higher. There is no change in the budget for the nominal case where everything goes well: the number of CI runs will be the same with or without speculative checks enabled.
However, in case of failure, there will be more jobs being run.
For example, if the PR #2 is broken and can't be merged, the job testing #1 + #2 and #1 + #2 + #3 will both fail. That will make Mergify schedule a new job testing #1 + #3.
In the end, the total number of jobs for this particular case is 4 (#1, #1 + #2, #1 + #2 + #3 and #1 + #3) whereas without speculative checks the number of jobs would have been 3 (#1, #1 + #2 and #1 + #3) — a 33% increase in the number of jobs.
This is your pact with the devil to get a faster merge queue.
The RCV Theorem 📜
We built a theory around the set of trade-off you have to do when configuring a merge queue. As with the CAP theorem for data stores, a merge queue has 3 properties:
- Reliability: only merge pull requests that are known to work individually and separately;
- Cheapness: run as few CI jobs as you can;
- Velocity: maximize throughput and minimize latency.
The tricks? Like with CAP, you can only pick 2 of those at the same time. We call that the RCV theorem.
In the previous section, we explored being reliable and cheap and reliable and fast by adjusting the number of speculative checks from 0 to infinity.
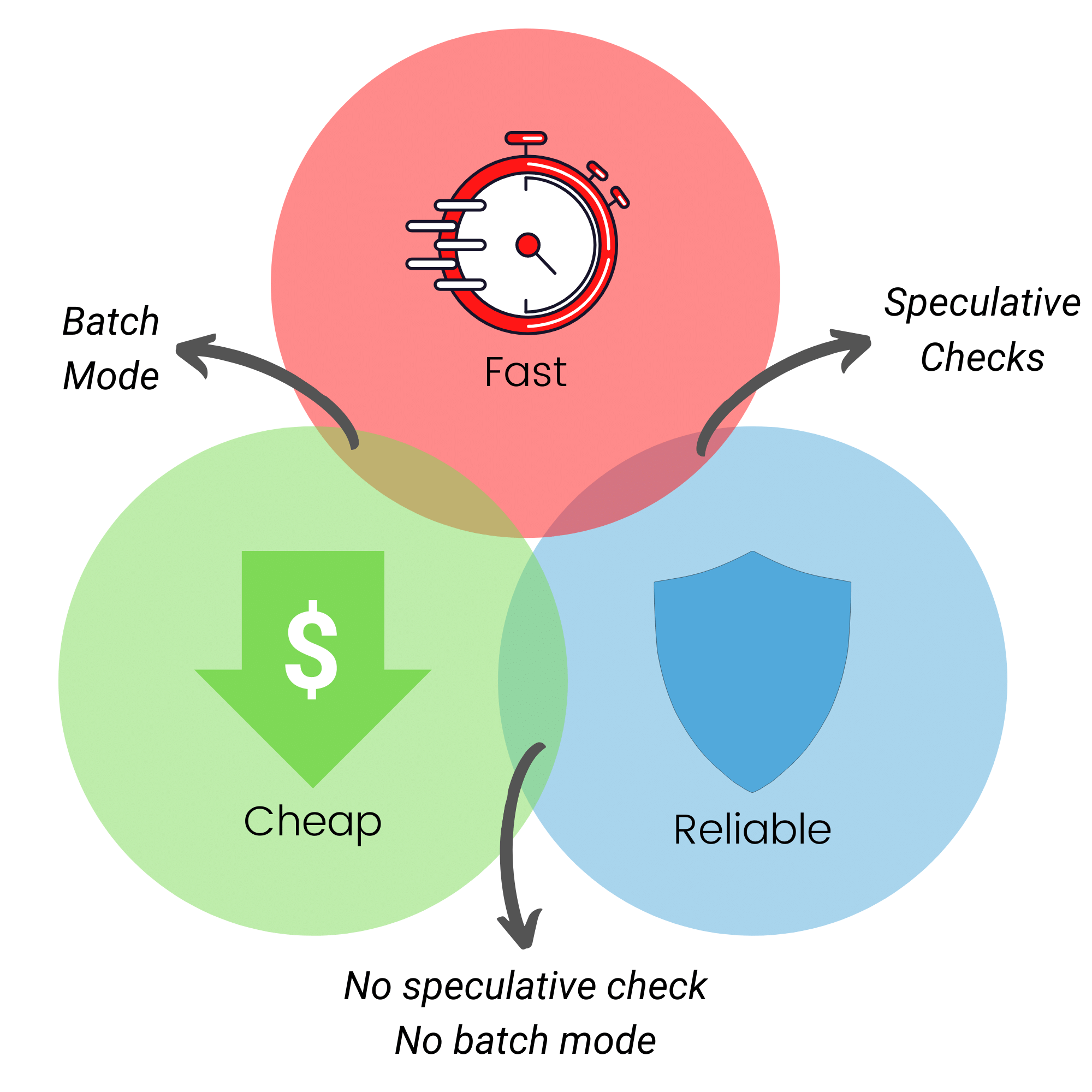
The question now is: how can you do cheap and fast (without losing too much reliability)?
Compromising: increase your merge throughput without increasing your CI budget
As you notice, with the speculative checks enabled, in our example, Mergify checked the combination of pull requests #1 + #2 + #3 — plus intermediary combination.
Now, if the latter passes the CI suite, it's possible but unlikely that one composing pull requests would fail if tested individually. If you are ready to make this trade-off, you can trade reliability for velocity.
To enable this feature, use the batch_size configuration option.
queue_rules:
- name: default
conditions:
- check-success=compile-and-test
speculative_checks: 1
batch_size: 3
pull_request_rules:
- name: merge using the merge queue
conditions:
- base=main
- "#approved-reviews-by>=2"
- check-success=compile-and-test
actions:
queue:
name: defaultIn our previous scenario, by using speculative_checks: 1 andbatch_size: 3, Mergify will not test #1 and #1 + #2 anymore, but only #1 + #2 + #3. If the latter passes, Mergify assumes #1 and #1 + #2 works too and merges all of those pull requests at the same time.
Using batch mode in our scenario changes the property of our queue to:
- 6 pull requests per hour of maximum throughput;
- 30 minutes minimum latency;
- 1-hour average latency;
- 2 hours maximum latency.
However, to merge our 10 pull requests, there would be only a need for 4 CI jobs in the nominal (no failure) scenario — rather than at least 10 using speculative or non-speculative checks — making it way cheaper.
Mixing Speculation and Batching
You might be wondering: and what if we'd use both mechanisms? Of course, you can! 🦾
queue_rules:
- name: default
conditions:
- check-success=compile-and-test
speculative_checks: 3
batch_size: 3
pull_request_rules:
- name: merge using the merge queue
conditions:
- base=main
- "#approved-reviews-by>=2"
- check-success=compile-and-test
actions:
queue:
name: defaultWith that option, you get a bit of both world: you can test 3 batches of 3 pull requests simultaneously. This means your merge queue has now:
- Maximum throughput of 6 pull requests per hour;
- Minimum latency of 30 minutes;
- Average latency of 33 minutes;
- Maximum latency of 1 hour.
Of course, it's a set of trade-offs: it's not entirely reliable since you're using batches and it's quite fast since you're using speculative checks, and it costs a little more than the nominal case.
Customizing
With all those settings, Mergify allows to finely-configure the CI budget used by the merge queue. Merging a lot of pull requests has never been so easy, fast, and safe!