What Is a Merge Queue?


Do you happen to know the common point between the open-source Node.js and Rust projects, the sporty social network Strava, the e-commerce company Shopify and the ride-hailing company Uber?
Their engineering team all rely on a merge queue.
Well, if you never heard of such a concept, you might be confused and wondering what it is and why they would even need that.
Before your mind starts racing and imagining some code waiting in line in front of a ticket office before being squashed, let me enlighten you.
Understanding The Problem
The fantastic engineering teams quoted above didn't suddenly create something named a merge queue for nothing. They hit a problem, and they all solved it using the same hammer. While the details of each implementation might differ, the key features remain the same.
To understand the problem, imagine a GitHub repository in the following situation: a pull requested is created, and it passes the CI.
This schema represents the state of the repository:
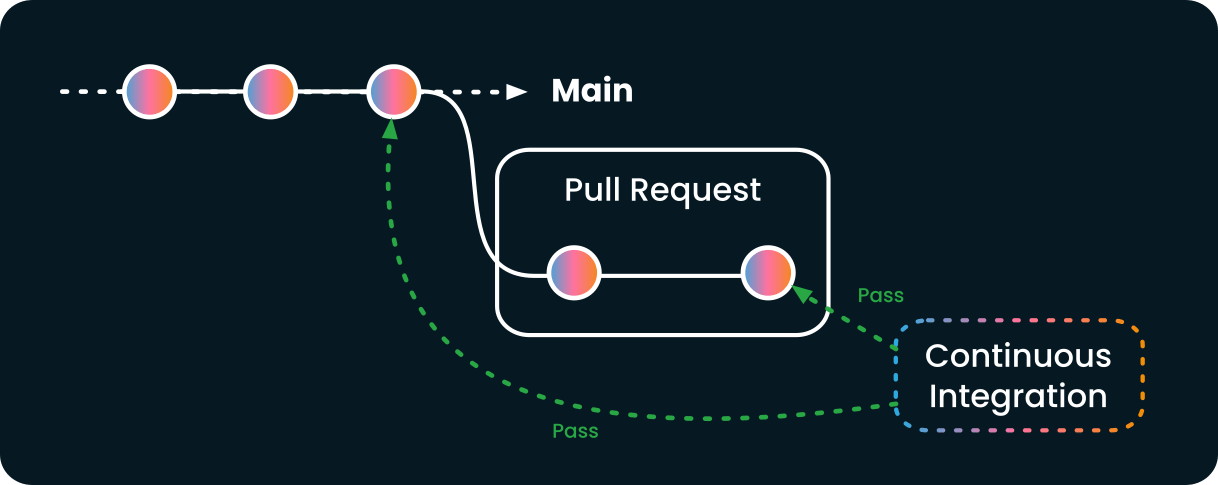
While the pull request is open, another commit is pushed to main. That new commit can be made directly to main or merged from another pull request; it doesn't matter. The result will be the same.
The tests are run against the main branch by the CI, and they pass. This schema illustrates the state of the repository and its continuous integration system:
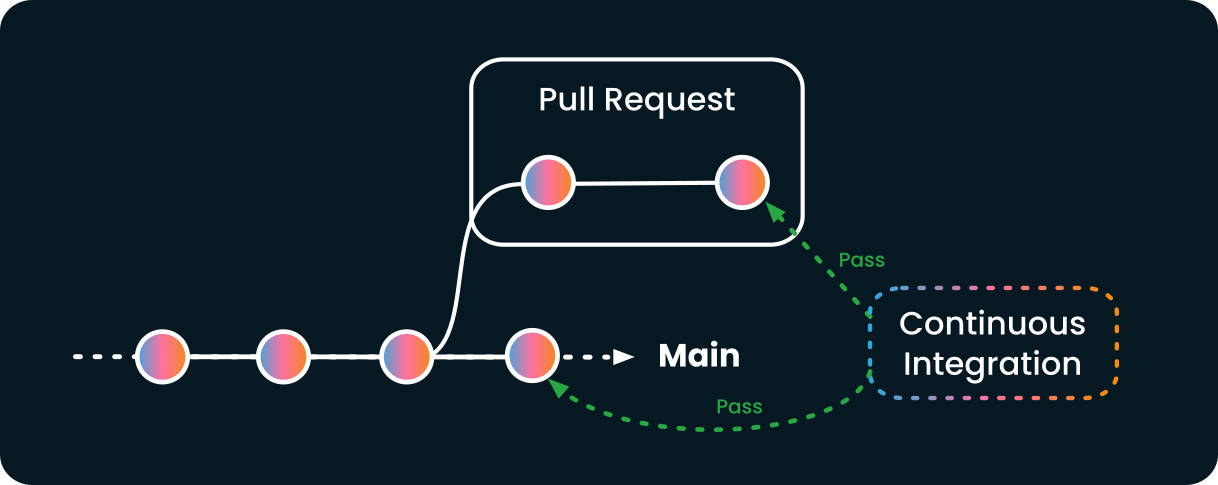
The pull request is still marked as valid by the continuous integration system since it did not change. As there is no code conflict, the pull request is considered as mergeable by GitHub: the merge button is green.
If you click that merge button, this is what might happen:
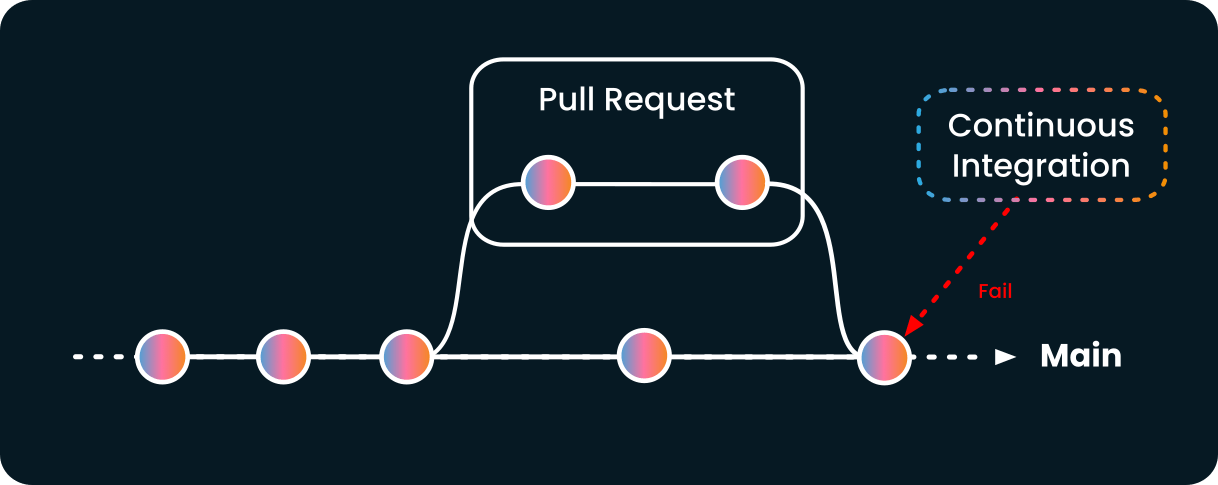
As the new merge happens, it is possible that the pull request that was once working breaks the main branch. The stalled pull request might introduce regression or breakages into the production system.
In one of their study, the Uber engineering team reports that while there is a 5% chance of an actual conflict between 2 changes, this number grows to 40% with only 16 concurrent and potentially conflicting modifications. With a large enough organization and codebase, this kind of problem starts happening every other day.
Using a Merge Queue
Using a merge queue solves that problem by updating any pull request that is not up-to-date with its base branch before it is merged. The update forces the continuous integration system to retest the pull request with the new code from its base branch, catching any potential regression.
In the previous example, if the repository used a merge queue, the queue system would have merged the main branch in the pull request, and the CI would have caught the regression before the merge.
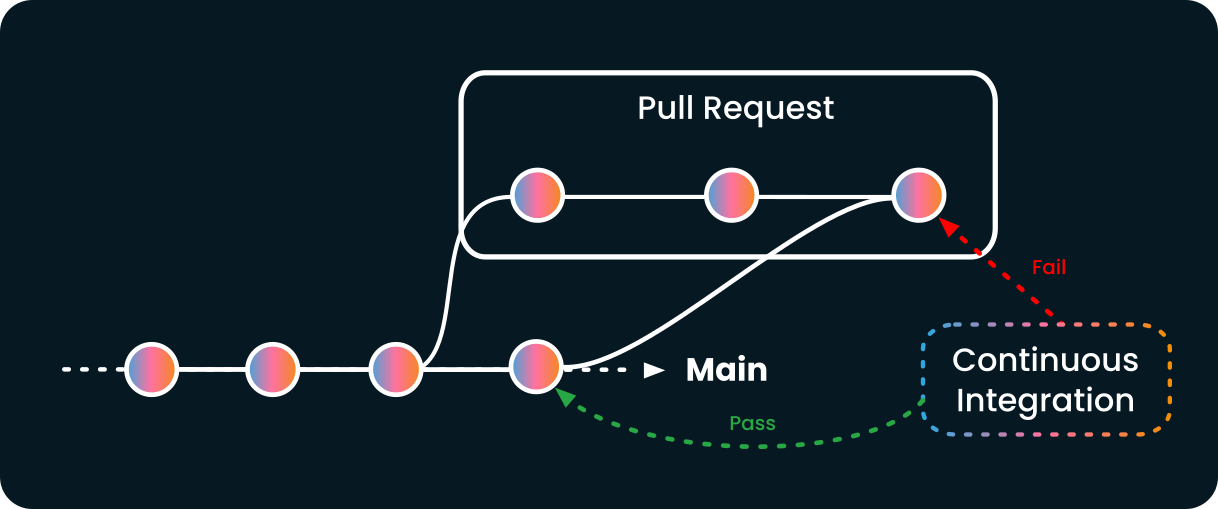
This mechanism is called a merge queue because every pull request ready to be merged is enqueued serially to be updated, tested, and then merged, one after another. That makes sure no surprise happens once the pull request is merged.
Why Using a Merge Queue
If you consider the ever-increasing size of your engineering team, its velocity at creating pull requests, and the emergence of bots that continuously generate code, the chance of breaking a production system arises as the system expands.
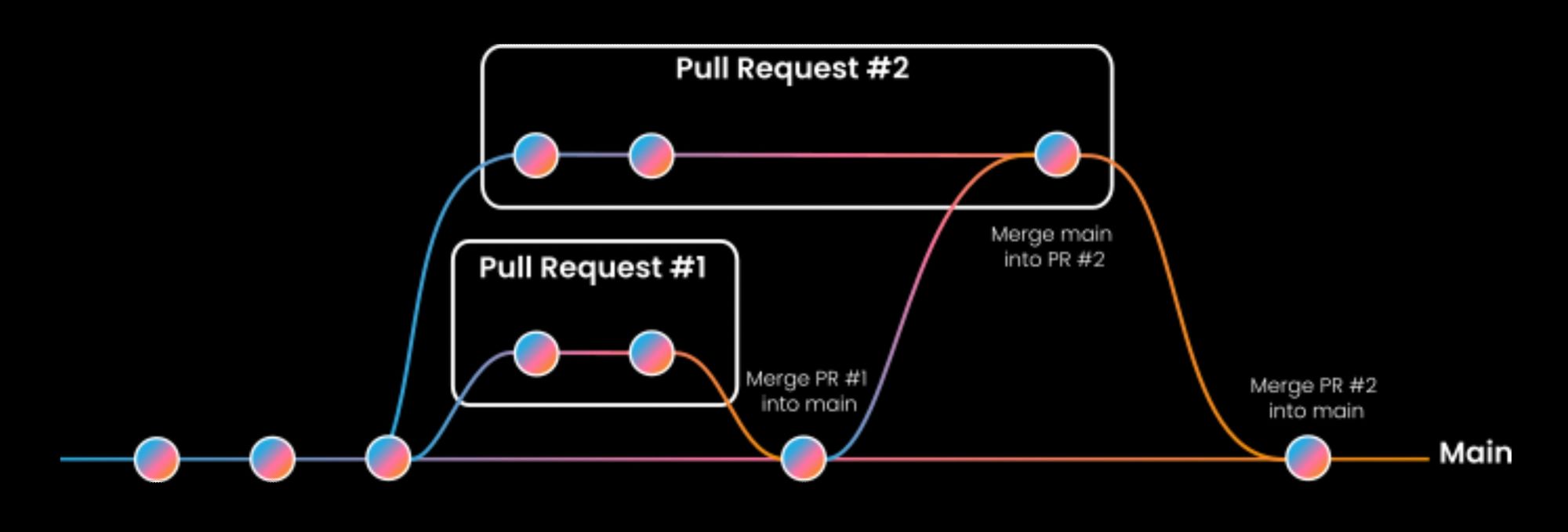
Over the last decade, the industry centered on building a pre-submit testing approach focused on individual changes and did not consider concurrent changes.
At Mergify, we envision that this has to change. The cost of faulty branches is too expensive, considering its consequences, such as delayed rollouts, deployment of rollbacks, and the hampering of productivity of developers due to local failure.
Mergify provides a merge queue for GitHub that is easy to set up and configure to your needs. It's free for open-source projects and comes with a 14 days free trial for private projects. Give it a try!