Streamline Operations with This Mergify Guide

Let's be honest—a broken main branch or a flaky test suite isn't just a minor annoyance. It's a massive productivity killer.
Every time a developer has to drop what they’re doing to fix a broken build or manually shepherd a pull request through a sea of checks, the ripple effects are felt across the entire team. This constant context switching is the hidden tax on your engineering velocity.
The problem runs deeper than just lost time. A disjointed workflow creates a culture of frustration. Developers become hesitant to merge code, fearing they might be the one to break the pipeline. This leads to longer lead times, delayed feature releases, and a team that spends more time firefighting than innovating.
Spotting the Real Bottlenecks in Your Process
Most development teams I've worked with face the same hurdles. They struggle with pull requests that sit stale for days, waiting for review. They deal with merge conflicts popping up from multiple developers touching the same files. And they watch helplessly as CI/CD costs spiral out of control due to inefficient test runs.
These are all symptoms of a larger problem: a lack of smart automation and clear visibility. Without a system to manage the flow of code changes, your team is left navigating a chaotic and unpredictable process. While you can build internal tools to help, exploring smart outsourcing development team solutions can also address broader workflow challenges and get projects moving faster.
The core issue isn't a lack of effort; it's the absence of a smart system. You can't expect developers to manually orchestrate dozens of pull requests, each with its own set of dependencies and checks, without something eventually falling through the cracks.
Below is a quick rundown of these common pain points and how a tool like Mergify directly addresses them.
Common Workflow Bottlenecks and Mergify Solutions
| Common Bottleneck | Impact on Operations | Mergify Solution |
|---|---|---|
| Manual PR Management | Developers waste time on repetitive tasks instead of coding. | Automated Rules to label, assign, and comment on PRs. |
| Merge Conflicts | Increased developer friction and delays merging features. | Merge Queue tests PRs against the latest main branch. |
| Inefficient CI Usage | High CI/CD costs and long waits for test results. | Speculative Checks & Batching group PRs to save runs. |
Broken main Branch |
Halts all development and erodes confidence in the pipeline. | Strict Merge Gating ensures only validated code gets in. |
This table shows that for every common frustration, there’s a targeted, automated solution that can get your team back on track.
A Smarter Way to Handle Pull Requests
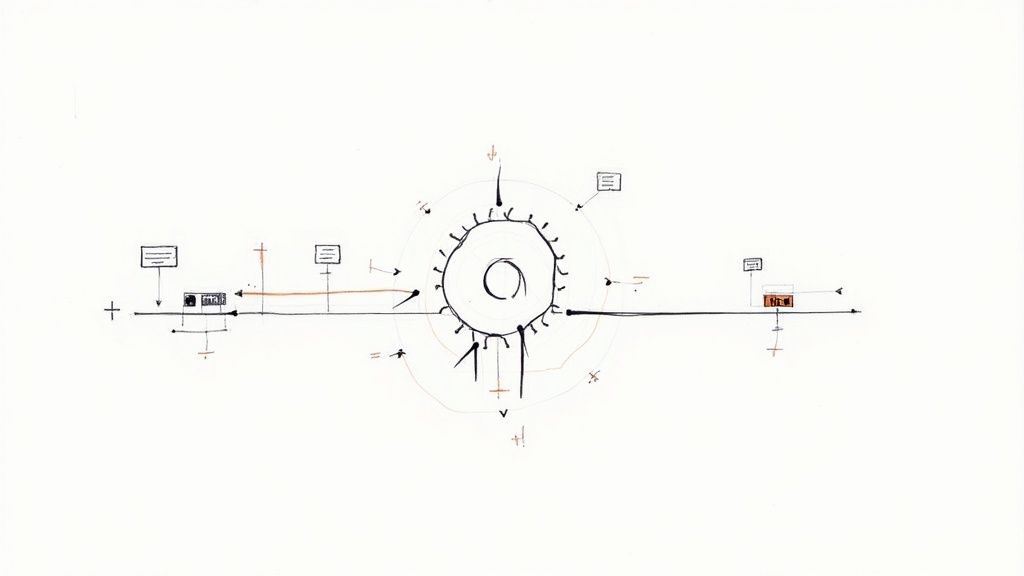
This is where a dedicated tool like Mergify really changes the game. It provides the automation layer needed to manage your workflow from the moment a pull request is opened to the second it’s merged.

The image above gives you a glimpse into this automated flow. It shows how the system can eliminate manual intervention, from updating PRs and batching CI checks to ensuring a stable main branch—all without a developer having to lift a finger.
Instead of relying on developers to remember a complex checklist, you can define your ideal workflow in a simple configuration file. Mergify then acts as an automated traffic controller for your codebase.
Here’s what that looks like in practice:
- Automated Prioritization: You can set rules to automatically merge critical bug fixes before new features. No more manual cherry-picking.
- Efficient Batching: Group compatible pull requests into a single CI run, which saves a surprising amount of time and money.
- Conflict Prevention: The Merge Queue is the star here. It ensures every PR is tested against the absolute latest version of the
mainbranch before merging, virtually eliminating the "it worked on my machine" problem.
By tackling these fundamental workflow issues, you create an environment where developers can focus on what they do best: writing great code. The rest of this guide will show you exactly how to configure Mergify to solve these problems and bring some much-needed order to your development process.
Configuring Your First Mergify Merge Queue
This is where the magic happens. You’ve read the theory, and now it’s time to configure your first Merge Queue. This is the moment you stop talking about a better workflow and actually start building one for your team.
The entire system is driven by a single file in your repository: .mergify.yml. Getting this file right is the key to unlocking a smoother, more predictable merge process.
Let's talk about a scenario I’ve seen countless times: a fast-moving team constantly tripping over itself. A developer finishes a feature, gets approval, but by the time they hit the merge button, someone else has already landed a change on the main branch. This kicks off a frustrating cycle of pulling the latest code, resolving conflicts, pushing again, and hoping for the best. It absolutely kills momentum.
This is the exact pain a Merge Queue is designed to eliminate.
The infographic below shows how these seemingly small manual tasks and backlogs can snowball, leading to major slowdowns and a surprising number of errors.
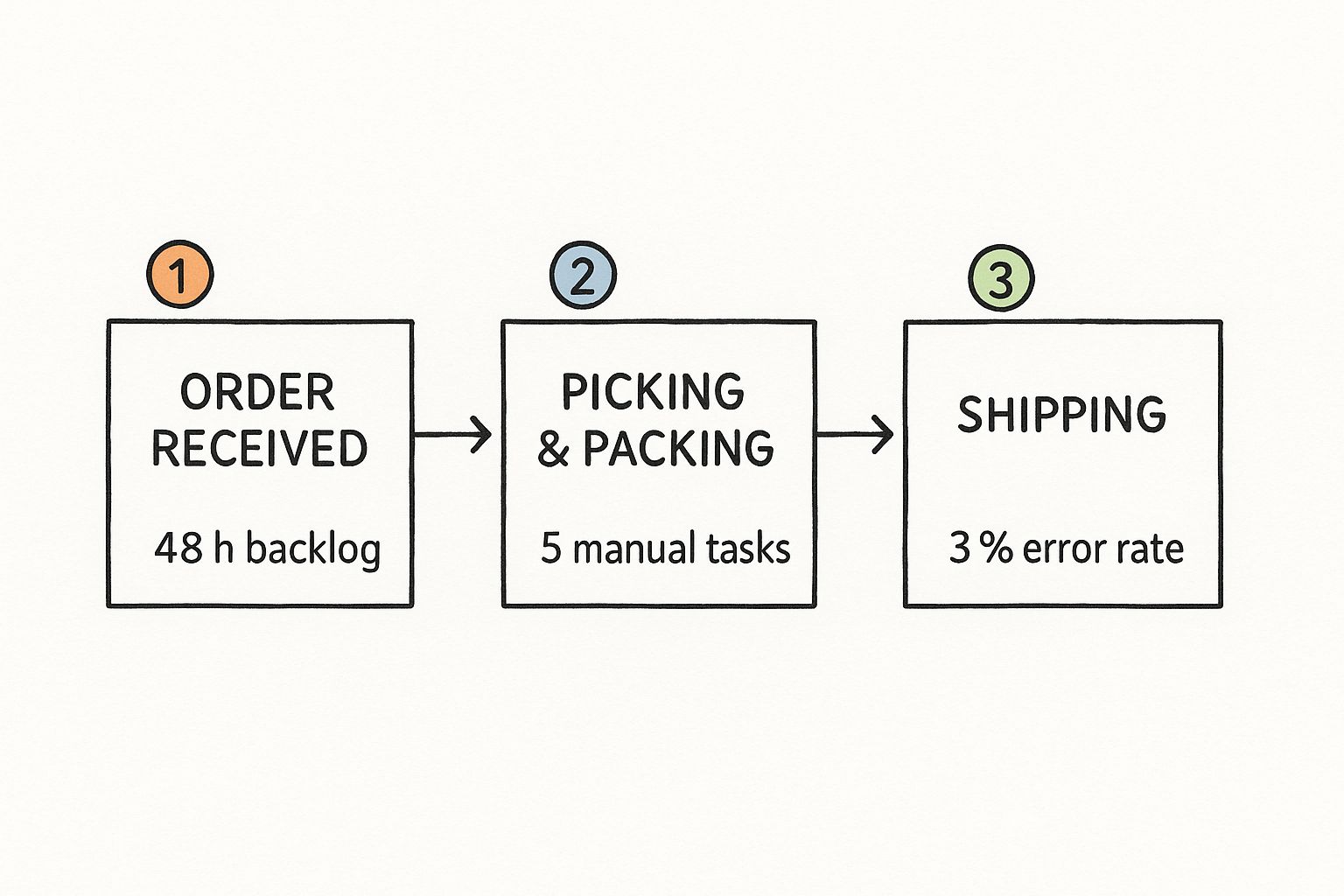
A 48-hour backlog might not sound like a disaster, but when you factor in manual overhead and a non-trivial error rate, you've got a serious bottleneck on your hands.
Your First YAML Configuration
Your journey starts by creating a .mergify.yml file at the root of your project. This file is your automated gatekeeper, containing a set of rules that tell Mergify exactly how to handle your pull requests.
Here’s a practical, real-world starter configuration to solve the conflict chaos we just talked about:
queue_rules:
- name: default conditions:
- "#approved-reviews-by>=1"
- check-success=ci-tests
pull_request_rules:
- name: Automatic merge on approval conditions:
- "#approved-reviews-by>=1"
- check-success=ci-tests actions: queue: name: default
This simple config does two powerful things. The queue_rules block defines a queue named default. Then, the pull_request_rules block tells Mergify that any pull request with at least one approval and a successful "ci-tests" check should be sent straight to that queue.
Just like that, you’ve ensured no PR can be merged without passing your essential quality gates.
Choosing Your Merging Mode
One of the most important decisions you'll make is picking the right merging mode for your queue. This choice directly impacts your team's throughput. Mergify offers a few options, but the two main ones you’ll consider are linear mode and speculative checks.
- Linear Mode: This is the most straightforward and safest approach. Mergify tests and merges one pull request at a time, guaranteeing each one is validated against the absolute latest version of the target branch. It's predictable, but it can create a bit of a line if your CI tests take a while.
- Speculative Checks: This mode is all about speed. Mergify creates temporary branches that assume the previous PRs in the queue will merge successfully. It then runs CI tests on these "speculative" branches in parallel. If a PR fails, it's booted from the queue, and the dependent checks are automatically restarted.
Pro Tip: From my experience, if your test suite is quick (under 10 minutes), linear mode is a fantastic starting point. It’s simple and effective. But if your tests are slow and you need to maximize throughput, speculative checks can be a total game-changer for your team’s velocity.
The trend toward automating repetitive work is only growing. As we look toward 2025, successful teams are the ones offloading predictable, time-sucking tasks to tools that can handle them better. This is a fundamental step toward real operational efficiency.
Putting It All Together for Your Team
With your .mergify.yml now in place, that chaotic manual merge process is replaced by an orderly, automated queue.
When a developer gets their PR approved, they don't merge it themselves. Instead, Mergify takes over. This is a crucial shift. It decouples the developer from the final, tedious merge step, freeing them up to grab the next ticket. No more babysitting pull requests.
This approach doesn't just solve merge conflicts; it introduces a new level of consistency to your entire pipeline. Teams working with complex CI/CD systems, for example, find this automation invaluable. You can even integrate Mergify with platforms like Jenkins to further centralize your pipeline management and make it even more robust.
Ultimately, configuring your first merge queue is the first, most important step in transforming your development workflow from a source of friction into a well-oiled machine.
Automating Tasks Beyond the Merge Button
A Merge Queue is a fantastic first step, but to really get your operations humming, you need to look past the merge button itself. Your team's workflow is probably full of small, repetitive tasks that, when you add them all up, eat a surprising amount of developer time. The real magic of Mergify is its knack for automating all that "workflow glue" that holds your process together.

Think about it. After a developer opens a pull request, what happens next? They might need to add specific labels, ping the right people for a review, or drop a comment to provide some context. Every one of these actions is a tiny distraction, a little context switch that pulls them away from what they do best: writing code. Automation takes care of all this administrative busywork, letting your engineers stay in the zone.
Intelligent Reviewer Assignment
Getting the right eyes on a pull request is one of the most common bottlenecks I see. It's especially tough in a big monorepo. A developer might have no idea who owns the src/billing/ directory or who the go-to expert is for *.css changes. This guessing game leads to delays as PRs sit unassigned or get bounced between teams.
You can fix this with a simple rule in your .mergify.yml file. Let's set up an action that automatically assigns the frontend team whenever CSS files are touched.
pull_request_rules:
- name: Assign frontend team for CSS changes conditions:
- files~=.css$ actions: review: users:
- frontend-lead-dev teams:
- frontend-team
- files~=.css$ actions: review: users:
With this rule live, every PR that modifies a CSS file is instantly routed to the right people. No more guesswork. No more delays. This simple bit of automation directly speeds up your feedback loop.
Automatic Labeling for Better Triage
Labels are much more than just colorful tags; they're vital for organizing and prioritizing work. A great practice is labeling PRs by size to quickly flag large, risky changes that might need a closer look. But let’s be honest, manually applying these labels is inconsistent and easily forgotten.
Mergify can handle this for you based on the number of lines changed.
Key Insight: Automating PR labeling isn't just about saving a few clicks. It establishes a standardized, machine-driven process that gives immediate context to everyone, from project managers to QA engineers. That consistency is a game-changer for effective project management.
Here’s a practical example that applies size/M or size/L labels automatically:
pull_request_rules:
- name: Label medium-sized PRs conditions:
- "#changes > 100"
- "#changes <= 500" actions: label: add:
- size/M
- name: Label large PRs conditions:
- "#changes > 500" actions: label: add:
- size/L
- "#changes > 500" actions: label: add:
This kind of automation ensures every single pull request is categorized the moment it's created. It gives your team an at-a-glance understanding of incoming work, all without any manual effort.
Effortless Backporting for Maintenance Releases
Managing maintenance branches can be a real grind. When a critical bug gets fixed in your main branch, you often have to port that same fix to older, supported versions like release/v2.1 or stable/1.9. This manual cherry-picking is tedious, error-prone, and just plain no fun.
Mergify can automate this entire process with a simple backporting action. Let's say you have a PR with the bug and must-backport labels. The following rule will automatically create new pull requests targeting your maintenance branches as soon as the original is merged.
pull_request_rules:
- name: Backport critical fixes conditions:
- merged
- label=bug
- label=must-backport actions: backport: branches:
- release/v2.1
- stable/1.9
Once the original PR gets merged, Mergify jumps into action, creating the backport PRs for you. This is a massive time-saver, especially for platform and SRE teams responsible for stability. The cost savings can also be huge; you can learn more about techniques for CI cost optimization in our guide.
These examples are just scratching the surface. The real goal is to spot any repetitive, rule-based task in your workflow and offload it. Beyond Mergify, your team can explore the top DevOps automation tools to build an even more efficient development ecosystem. By automating these smaller tasks, you free up your team’s most valuable resource: their time and focus.
You can't fix what you can't see. Automating your merge process is a massive win, but to really dial in your operations, you need a clear view of what’s happening under the hood. A slow or unreliable continuous integration (CI) pipeline is a silent killer of productivity, and pinpointing the exact cause often feels like searching for a needle in a haystack.
This is where data becomes your best friend. Without it, you’re just guessing. You might suspect a certain test suite is slow or that a specific job is "flaky," but you don't have the hard evidence to prove it and take decisive action. It’s a reactive loop so many teams get stuck in—waiting for something to break, then scrambling to fix it.
Mergify's CI Insights dashboard was built to break that cycle. It turns your pipeline from a black box into a transparent, measurable system. By handing you clear, actionable data, it helps your team shift from being reactive firefighters to proactive performance tuners.
From Data Points to Actionable Insights
The CI Insights dashboard doesn't just throw raw numbers at you; it helps you spot trends and identify your biggest bottlenecks.
Imagine your dashboard highlights a specific E2E (end-to-end) test that fails 30% of the time on its first run but almost always passes on a retry. That's a classic "flaky" test. Manually, this problem creates huge frustration and wastes CI minutes as developers are forced to re-run the entire pipeline over and over.
Armed with this data, you can take targeted action:
- Isolate the Flakiness: You now have concrete evidence to justify dedicating engineering time to fix this unreliable test.
- Automate the Retry: Instead of manual retries, you can create a Mergify rule to automatically re-run only that specific flaky job, saving time and CI credits.
You don't have to overhaul your entire testing strategy overnight. The goal here is to make small, data-driven improvements that compound. Fixing one flaky test might save your team 10 minutes a day, which adds up to over 40 hours of recovered engineering time per year.
This data-driven approach is a core part of modern pipeline management, and it's where the whole industry is heading. The global data pipeline market is projected to grow from $12.26 billion in 2025 to a massive $43.61 billion by 2032. This explosive growth just underscores how critical pipeline visibility and control have become.
Identifying Your Slowest CI Jobs
Another critical piece of the puzzle CI Insights gives you is job duration. You might be surprised to discover that a seemingly harmless setup job is tacking on five unnecessary minutes to every single pull request check.
Once you spot the slowest parts of your pipeline, you can start asking the right questions:
- Can we parallelize this slow job?
- Is there a dependency that could be cached more effectively?
- Can we run this job only when specific files are changed?
For instance, if your build-android-app job takes 15 minutes but is only needed when files in the /android directory change, you can configure your CI provider to run it conditionally. That single change can drastically slash the wait time for frontend or backend-only PRs, creating a much more efficient workflow for most of your team.
For teams looking to perfect their setup, understanding continuous integration best practices is key to driving results. Insights from your dashboard provide the real-world feedback needed to apply these practices where they'll have the most impact.
Turning Insights into Proactive Automation
The real magic happens when you pair CI Insights with Mergify’s automation engine. This is where you connect the "what" with the "how."
| Insight from Dashboard | Corresponding Mergify Action |
|---|---|
| Flaky Test Identified | Automatically re-run the failed job a set number of times. |
| Long-Running Job Found | Prioritize PRs that don't trigger the slow job. |
| High CI Failure Rate | Immediately alert the on-call engineer via a comment on the PR. |
| Fast-Passing PRs | Automatically queue PRs with quick checks ahead of others. |
This proactive approach fundamentally changes your team’s relationship with its CI/CD pipeline. Instead of being a source of frustration, it becomes a reliable, optimized asset that actively accelerates your development cycle. By using data to find and fix the small leaks, you build a resilient system that helps you consistently ship code faster and with far more confidence.
Fine-Tuning Your Workflow with Smart Scheduling
Once your foundational automations are in place, it’s time to graduate from a good process to a great one. This is where you move beyond simple rules and start building a truly intelligent workflow. Advanced scheduling is about more than just merging pull requests; it’s about merging the right pull requests at the right time to maximize your team's impact.

Think about the natural rhythm of your development cycle. Not all pull requests are created equal. A critical hotfix for a production bug shouldn't be stuck waiting in line behind a low-priority feature enhancement. In the same way, a pull request from a senior engineer with a solid track record might be considered lower risk than one from a new contributor. Smart scheduling lets you encode this kind of business logic directly into your merge process.
Prioritizing Pull Requests by Importance
Your merge queue doesn't have to be a simple "first-in, first-out" line. With Mergify, you can assign different priority levels to pull requests based on all sorts of conditions. This is how you make sure your most critical work always jumps to the front of the queue.
For instance, let's say your team uses a hotfix label for urgent bug fixes. You can easily create a high-priority rule just for them.
queue_rules:
- name: hotfix conditions: []
- name: default conditions: []
pull_request_rules:
- name: Queue critical hotfixes with high priority conditions:
- "#approved-reviews-by>=1"
- check-success=ci-tests
- label=hotfix actions: queue: name: hotfix priority: high
- name: Queue regular pull requests conditions:
- "#approved-reviews-by>=1"
- check-success=ci-tests actions: queue: name: default priority: medium
This setup creates two distinct queues. Any PR labeled hotfix gets routed to the "hotfix" queue with high priority, while all other approved PRs land in the "default" queue with medium priority. It's a simple change, but it guarantees that urgent fixes are never blocked by routine development.
Batching Pull Requests to Cut CI Costs
One of the most powerful features for fine-tuning your workflow is batching. Instead of running a full CI pipeline for every single pull request, Mergify can intelligently group several compatible PRs and test them in a single, combined run. For any team looking to slash CI expenses and shorten the total time-to-merge, this is a game-changer.
The efficiency gains here are dramatic. In a manual system, five approved PRs might trigger five separate CI runs. With batching, those same five PRs could be tested together in one go, potentially cutting your CI usage by 80% for that group.
Batching isn't just a cost-saving measure; it’s a throughput accelerator. By reducing the number of individual CI runs, you free up your build agents faster, allowing the entire team to move more quickly. The overall time from PR approval to deployment shrinks significantly.
Here’s how you can enable batching in your default queue:
queue_rules:
- name: default conditions: [] speculative_checks: 5 batch_size: 5 In this example, we’ve updated the
defaultqueue to both use speculative checks and create batches of up to five pull requests. Mergify will now try to group compatible PRs, test them as a unit, and merge them all at once. This is a simple but incredibly effective way to make your CI process more efficient.
Creating Complex Layered Conditions
You can combine these concepts to build a highly customized merge strategy that truly reflects your team's specific needs. Maybe you want to give PRs from your senior developers a slightly higher priority, but not as high as a critical hotfix.
Let's look at a sophisticated, multi-tiered priority system:
| Priority Level | Condition | Mergify Action |
|---|---|---|
| Critical | PR has hotfix label. |
Place in hotfix queue with priority: high. |
| High | PR author is a senior dev. | Place in default queue with priority: high. |
| Medium | Standard approved PR. | Place in default queue with priority: medium. |
| Low | PR only modifies docs. | Place in default queue with priority: low. |
This kind of layered logic allows you to fine-tune your operations with real precision. It ensures your automation reflects the same nuanced decisions a team lead would make, but it does so instantly and consistently, every single time. By setting up these smart scheduling rules, you transform your merge process from a simple gatekeeper into an intelligent, performance-optimizing engine that works for you around the clock.
Mergify FAQ for Engineering Teams
When you're thinking about bringing in new automation, questions are going to pop up. That's a good thing. Getting straight answers is how you build confidence and make sure the whole team is on board for a smooth rollout.
This FAQ covers the common questions we hear from engineering teams looking to get their workflows in order with Mergify. We'll tackle real-world scenarios to help you see the path forward.
How Is Mergify's Merge Queue Different from GitHub's?
This is a great question. While both Mergify and GitHub want to protect your main branch, the real difference comes down to the depth of control and intelligence you get. GitHub's native merge queue is a solid starting point, but many teams find they quickly outgrow it and need something more powerful and customizable.
Think of it like this: GitHub’s queue is a standard traffic light. It lets one car go at a time, which is better than nothing. Mergify, on the other hand, is a full-blown traffic control system. It can create express lanes for hotfixes, reroute traffic based on what's inside (like a small bug fix versus a massive feature), and even group compatible cars to move through the intersection all at once.
This level of control is possible because Mergify’s YAML configuration is incredibly flexible. You can build rules for just about any scenario, including:
- Complex Prioritization Rules: You can set it up so a critical bug fix always jumps to the front of the line, merging before that new feature your team has been working on for weeks.
- Advanced Merging Strategies: You can choose your own adventure. Optimize for speed with speculative checks, or save on CI costs by batching pull requests. The choice is yours.
- Detailed CI Insights: Mergify actually shows you what’s going on with your pipelines, helping you spot flaky tests and bottlenecks. The native GitHub queue doesn't offer this.
For any team that needs to fine-tune its workflow beyond the basics, Mergify provides the granular control you need to build a truly optimized process.
Can Mergify Actually Help Reduce Our CI/CD Costs?
Yes, absolutely. For many teams, this is one of the most immediate and tangible benefits they see. The savings come from a few different places, all of which target the most common sources of wasted CI/CD spending.
We often see growing teams struggling to manage their CI pipeline costs. Without any optimization, those costs can easily scale right alongside—or even faster than—your team size and output.
Mergify hits this problem head-on in three key ways:
- Batch Merging: This is the big one. Instead of firing off a full CI pipeline for every single approved PR, Mergify is smart enough to group compatible pull requests and test them together in a single CI run. This can slash the total number of CI jobs your team runs every day.
- Flaky Test Management: Our CI Insights feature helps you pinpoint those annoying flaky tests that trigger needless pipeline reruns. With that data, you can create rules to automatically retry just the failed job, not the entire test suite. That saves a surprising amount of time and money.
- Developer Time Savings: When the merge process is fully automated, your developers are freed from the mind-numbing task of watching pipelines and babysitting their pull requests. That’s expensive engineering time you can pour back into building great features.
What Is the Best Way to Roll Out Mergify to a Large Team?
For larger organizations, a phased rollout is almost always the right move. Trying to flip the switch on a complex, org-wide configuration all at once can create more friction than it's worth. A gradual approach builds momentum and makes for a much smoother transition.
I always recommend starting small. Pick one non-critical repository for a pilot project and get a small group of "developer champions" to lead the charge on the initial setup.
Here’s how I’d structure that pilot project:
- Start with Simple Automations: Begin with the low-hanging fruit. Set up some basic rules, like automatically labeling pull requests or assigning reviewers. This gives you an instant win without touching the core merge process just yet.
- Introduce the Merge Queue: Once the team is comfortable, turn on the Merge Queue. Keep the configuration permissive and low-risk at first.
- Document and Share Wins: Make sure you document your
.mergify.ymlconfiguration and share the early successes—like time saved or merge conflicts avoided—with the rest of the engineering org.
This pilot project becomes your battle-tested template and a powerful internal case study. It generates real buy-in and makes rolling Mergify out to other repositories much faster and more predictable.
Ready to stop babysitting pull requests and build a workflow that actually works for you? Mergify gives your team the power to automate, prioritize, and protect your codebase with an intelligent Merge Queue and powerful CI/CD optimizations. Start your free trial today and see how much faster your team can move.