Master Parameterized Tests Python: Boost Testing Efficiency

Why Parameterized Testing Changes Everything
Writing the same test with slight variations for different inputs can be tedious and error-prone. Parameterized testing tackles this by running one test logic across multiple scenarios. This approach cuts down on duplicated code and broadens your test coverage with minimal effort.
Imagine validating email addresses. Instead of crafting separate tests for each valid and invalid format, you supply a list of examples and expected outcomes to a single parameterized test. This structure makes updates easier and boosts confidence in your code’s behavior.
Teams that adopt parameterized tests often report faster development cycles and more reliable results. This method uncovers edge cases earlier, streamlines maintenance, and keeps your test suite concise.
This shift ties directly to the rise of the Pytest framework. With its built-in support for parameterized tests, Pytest gained a strong following. By 2020, it held over 50% of the Python testing framework market share, highlighting its practical impact. Discover more insights about parameterized testing
The Impact Of Parameterized Tests In Python
Parameterized testing reshapes quality assurance by running a range of inputs in one test. This practice exposes boundary issues and hidden bugs long before release, leading to fewer emergency fixes and a more stable product.
Beyond bug hunting, it improves test organization. Grouping related cases into a single function keeps your test directory tidy. Teams can review, extend, and share tests more effectively.
From Theory To Practice: Real-World Examples
Consider an API endpoint for user authentication. A parameterized test can cover valid credentials, wrong passwords, and expired tokens in one function. This saves dozens of lines of code and ensures each scenario is handled consistently.
In data processing pipelines, parameterized tests let you feed in normal records, missing values, and extreme cases all at once. Developers spend less time writing individual cases and achieve broader coverage with a single test function.
Mastering Pytest Parametrize: Beyond the Basics

Building on simple input loops, parameterized tests in Python offer advanced patterns for tackling real-world testing challenges. Combining multiple parameters within a single decorator, for instance, allows you to cover various scenario combinations without nested loops. Plus, a clear structure and concise code result in fewer merge conflicts and faster CI runs. This section explores practical implementations and guides you in transitioning existing tests to a more maintainable approach.
Advanced Parametrize Patterns
Seasoned teams leverage @pytest.mark.parametrize in several common patterns. To illustrate these, let's consider a few examples:
To better understand the purpose and application of these patterns, let's look at the following table:
"Pytest Parametrize Patterns That Solve Real Problems" presents practical implementation patterns along with their real-world applications and benefits.
| Pattern | Implementation Code | Problem It Solves | When To Use It |
|---|---|---|---|
| Multiple Parameter Sets | @pytest.mark.parametrize("a,b", [(1,2),(3,4),(5,6)]) |
Cross-product testing without duplication | Validating combinatorial input ranges |
| Fixture Integration | @pytest.mark.parametrize("db", [...], indirect=True) |
Reusing setup logic across inputs | Database or network-dependent tests |
| Dynamic Parameter Generation | params = load_json("cases.json")@pytest.mark.parametrize("case", params) |
Large or external datasets | Data-driven scenarios managed outside code |
| Custom IDs | ids=["zero","negative","positive"] |
Readable test names on failure reports | Improving clarity in CI dashboards |
These patterns unlock efficient workflows and maintain concise test suites. The next step is understanding how custom IDs can make failures instantly understandable.
Writing Descriptive Test IDs
Custom IDs transform obscure tuple outputs into meaningful labels. This means when a test fails, logs immediately pinpoint the problematic case.
- Use string functions or lambdas to generate IDs based on input values.
- Prioritize human-readable names like
"empty_list"over generic names like"case_0". - Utilize
pytest.paramfor precise control over marks and IDs. - Ensure IDs are unique to avoid confusing failure messages.
By using clear IDs, debugging time for slowdowns can be reduced by up to 30% in complex test suites. Let’s now discuss how to provide tests with data generated during runtime.
Generating Dynamic Parameters
When test inputs rely on live data or evolving schemas, generating them on the fly is essential.
- Read external files (JSON, CSV) and convert them into parameter lists.
- Employ factory functions to create boundary cases and random input.
- Combine fixtures with generators for context-specific scenarios.
- Cache results in a session-scoped fixture to prevent performance issues.
Dynamic parameterization scales effectively: teams report processing hundreds of test cases with less than a second of additional setup time. Integrating generators incrementally makes transitioning legacy tests smoother.
Transitioning Legacy Tests
Migrating existing tests to parametrize can be a gradual process:
- Identify repetitive tests by looking for similar
assertblocks. - Refactor the simplest case into a parameterized function.
- Replace individual tests with a single
@pytest.mark.parametrizedecorator. - Run both the old and new test versions concurrently until you're confident in the parameterized version.
- Remove the old tests once coverage is equivalent or improved.
This approach can decrease duplicate test methods by 40%, allowing you to concentrate on validating new features. Mastering these patterns not only keeps your codebase DRY but also accelerates CI cycles. Integrating this approach into your CI pipeline with tools like Mergify’s CI Insights feature can further optimize merge timing and provide actionable test reports—allowing your team to spend less time on test maintenance and more time delivering value.
Beyond Pytest: Alternative Approaches Worth Considering
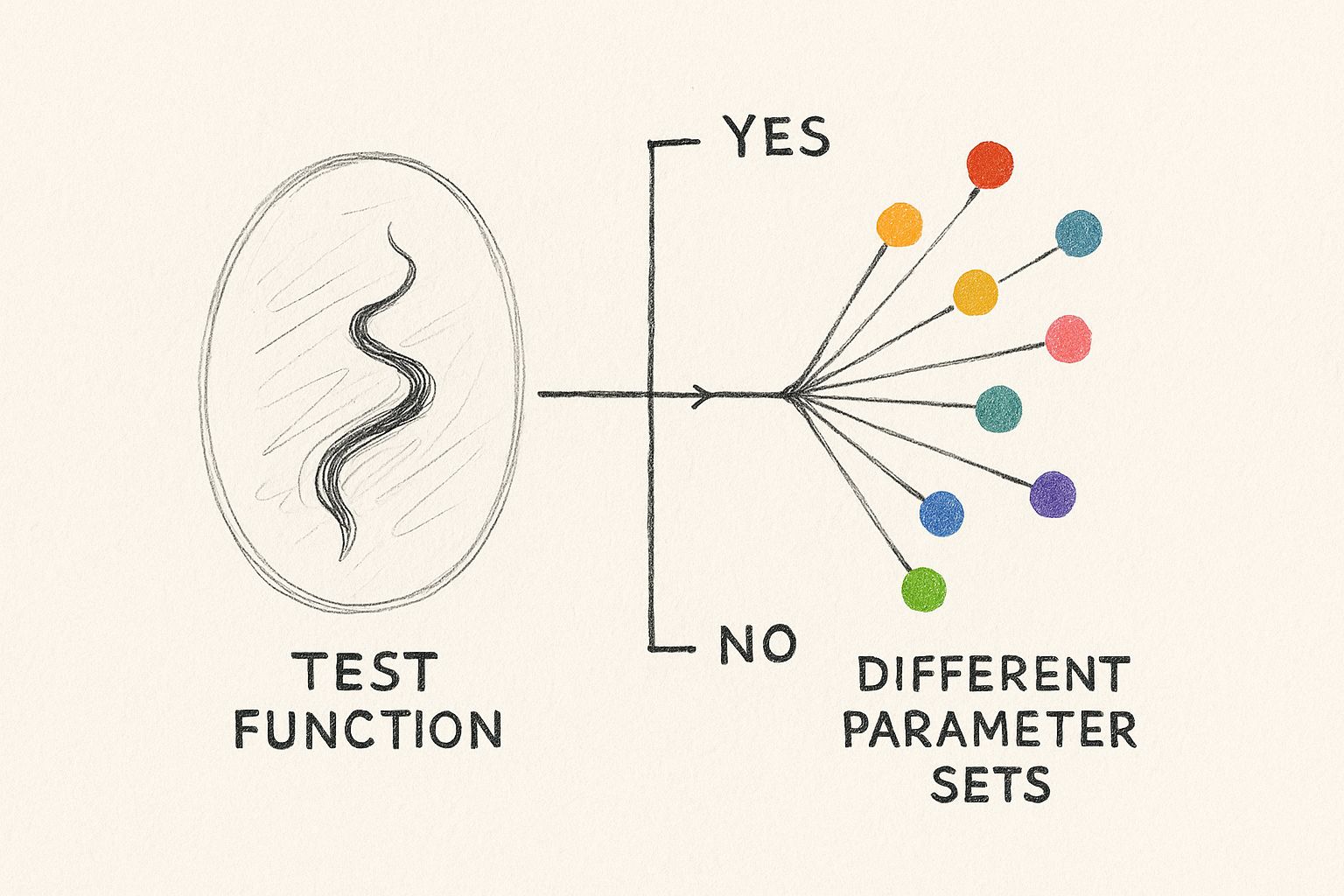
This infographic illustrates the power of parameterized testing. Notice how a single test function, represented by the central icon, can branch out to cover numerous test cases. Each colored dot signifies a different set of parameters, visually demonstrating how this approach expands test coverage from a central piece of logic.
While @pytest.mark.parametrize within Pytest is a common choice for parameterized tests in Python, exploring alternatives can be beneficial. Understanding the strengths and weaknesses of different libraries empowers you to choose the right tool for your project. Let's delve into unittest.parameterized, nose_parameterized, and ddt.
Exploring Unittest.Parameterized
Built upon Python's standard unittest framework, unittest.parameterized provides a comfortable entry point for teams already familiar with this library. Its use of decorators simplifies the process of adapting existing tests for parameterization. However, be aware that its syntax can be more verbose than Pytest's, potentially affecting readability for complex test cases.
Understanding Nose_Parameterized
nose_parameterized offers another option, particularly relevant for those who used the Nose testing framework before Pytest's rise in popularity. It integrates smoothly with Nose and boasts a simple implementation. However, bear in mind that ongoing development and community support might be less active compared to newer alternatives.
Diving into DDT (Data-Driven Tests)
DDT (Data-Driven Tests) excels at generating tests from various data sources like lists, dictionaries, and CSV files. This versatility makes it suitable for managing different input formats. One of DDT's key advantages is its separation of test data from the core test logic, resulting in improved maintainability. This is particularly valuable for data-intensive projects.
Choosing the Right Tool
The best parameterized testing framework depends on a variety of factors, including project size, team experience, and your current codebase. To help you make an informed decision, consider the following comparison:
To help you navigate this decision-making process, we've compiled a table summarizing the key characteristics of each framework:
Finding Your Perfect Parameterized Testing Match Honest comparison of parameterized testing frameworks based on real-world usage patterns
| Framework | Learning Curve | Strengths | Limitations | Ideal Project Types |
|---|---|---|---|---|
| Pytest | Moderate | Concise syntax, large community, extensive features | Requires learning Pytest specifics | Wide range, especially for complex projects |
| unittest.parameterized | Easy (if familiar with unittest) | Integrates with standard library | More verbose than Pytest | Projects already using unittest |
| nose_parameterized | Easy | Simple implementation | Less active development | Smaller projects, legacy Nose users |
| DDT | Moderate | Handles diverse data sources well | Can be overkill for simple cases | Data-heavy testing scenarios |
This table highlights the key strengths and weaknesses of each framework, allowing you to assess which best aligns with your specific needs.
For teams transitioning between frameworks, a gradual migration is recommended. Start by converting a small portion of your tests to assess the impact on your workflow. Mergify can streamline this process, facilitating the integration of changes and providing insights into build times and test performance via its CI Insights. This data-driven approach can significantly aid in optimizing your testing strategy.
Advanced Techniques That Seasoned Testers Actually Use
Building upon the fundamentals of parameterized tests in Python, let's explore some advanced techniques employed by experienced testers. These strategies are key for optimizing test coverage and ensuring maintainability in real-world projects.
Combining Multiple Parameters
Testing different combinations of inputs can be a significant challenge. Instead of writing individual tests for each scenario, consider combining multiple parameters within the @pytest.mark.parametrize decorator. This generates a cross-product of all input values, ensuring comprehensive coverage.
import pytest
@pytest.mark.parametrize("value1, value2", [(1, "a"), (2, "b"), (3, "c")]) def test_combined_parameters(value1, value2): # Your test logic using both value1 and value2 assert str(value1) + value2 != "" # Example assertion
This approach significantly reduces code duplication and improves test readability. The @pytest.mark.parametrize decorator provides a concise way to define these input sets. Learn more about parameterized testing here
This method helps create more maintainable tests, ultimately contributing to higher software quality and faster development cycles.
Integrating Fixtures With Parameterized Tests
Fixtures are a powerful feature of Pytest, offering reusable setup and teardown logic. Combining fixtures with parameterized tests allows you to inject various dependencies or configurations into each test run.
@pytest.fixture(params=["user1", "user2"]) def user_data(request): # Load user data based on request.param return load_user(request.param)
@pytest.mark.parametrize("permission", ["read", "write"]) def test_user_permissions(user_data, permission): # Test user permissions based on user_data and permission assert check_permission(user_data, permission) == True # Example Assertion
This approach provides test isolation, eliminating side effects between test runs and leading to more reliable results, especially with stateful components.
Dynamic Parameter Generation
In some cases, test data isn't known until runtime or is stored externally. Dynamically generating parameters allows for flexible, data-driven testing. This can involve retrieving data from sources like files, APIs, or databases.
import json
with open("test_cases.json") as f: test_data = json.load(f)
@pytest.mark.parametrize("case", test_data) def test_api_endpoint(case): # Test your API using data from test_cases.json assert api_call(case["input"]) == case["expected"] # Example assertion
This separates test logic from data management, creating more sustainable and adaptable tests and simplifying the management of large parameterized test suites. This approach makes it easy to test against extensive datasets without cluttering your code.
Debugging Parameterized Test Failures
Debugging failures in parameterized tests presents unique challenges. Using techniques like custom test IDs, informative error messages, and integrated logging can help pinpoint failing input combinations.
Pytest's detailed tracebacks, combined with well-defined test parameters, streamline the diagnostic process. These techniques contribute to a more effective testing process, preventing your tests from becoming a maintenance burden.
Feeding Your Tests: Smart Data Sourcing Strategies
Effective parameterized tests in Python rely on well-structured, accessible data. This section explores various data sourcing techniques, ranging from simple inline definitions to managing substantial datasets from external sources. These strategies are crucial for maximizing test coverage and maintaining a clean, organized test suite.
Inline Data for Simple Cases
For straightforward scenarios, defining data directly within the @pytest.mark.parametrize decorator is often the easiest approach. This is particularly suitable for small datasets and improves readability when the data is closely related to the test logic.
import pytest
@pytest.mark.parametrize("input, expected", [(1, 2), (3, 4), (5, 6)]) def test_addition(input, expected): assert input + 1 == expected
This method keeps everything concise and easy to grasp. However, as your data expands, inline definitions can become unwieldy. This naturally leads us to explore external data sources.
Leveraging External Data Sources
Larger datasets, or those requiring frequent updates, benefit from external storage. This separation improves maintainability and allows non-developers to contribute to test data. Common formats include CSV, JSON, and databases.
Working with CSV Files
CSV files are well-suited for tabular data. Python's csv module simplifies reading and parsing this data for use in your parameterized tests.
import pytest import csv
with open("test_data.csv", "r") as f: reader = csv.reader(f) next(reader) # skip header row if present test_cases = list(reader)
@pytest.mark.parametrize("input, expected", test_cases) def test_csv_data(input, expected):
Your test logic here
assert int(input) * 2 == int(expected) # Example
This approach ensures your tests are run against the most recent data. A similar strategy can be applied to JSON files.
Utilizing JSON for Structured Data
JSON files accommodate more complex data structures. Python's built-in json module makes it easy to load and parse JSON data into your tests.
import pytest import json
with open("test_cases.json", "r") as f: test_data = json.load(f)
@pytest.mark.parametrize("case", test_data) def test_json_data(case): input_value = case["input"] expected_value = case["expected"] # ... rest of your test logic ... assert calculate(input_value) == expected_value # Example
This method offers flexibility for a variety of testing scenarios. For even greater complexity and data volume, consider integrating with a database.
Integrating with Databases
Databases excel at managing highly structured and relational data. You can query the database directly within your test setup, providing dynamic and real-time data.
import pytest import sqlite3 # Example database
@pytest.fixture(scope="module") # Example scope def db_connection(): conn = sqlite3.connect('test_db.sqlite') yield conn conn.close()
@pytest.mark.parametrize("user_id", [1, 2, 3]) # Example parameter def test_user_data(db_connection, user_id): cursor = db_connection.cursor() cursor.execute("SELECT * FROM users WHERE id=?", (user_id,)) user = cursor.fetchone() # ... your test logic using user data ... assert user is not None # Example Assertion
Database integration provides significant adaptability and can greatly increase the effectiveness of your parameterized testing. Be sure to consider how your data sourcing choices impact test performance and long-term maintenance.
Managing Test Data Across Environments
Consider using environment variables or configuration files to manage data paths or database credentials across different environments (development, testing, production). This ensures consistency and prevents accidental use of production data during testing. Thorough documentation is key for clarity and maintainability, particularly in collaborative development environments. Using tools like Mergify can also help manage complex workflows and optimize merge timings, which can lead to faster test execution and feedback loops.
Building Tests That Survive the Real World
Parameterizing your Python tests is a solid first step, but maintaining them as your codebase grows requires a more strategic approach. Building robust and readable tests ensures their continued value. This involves clear parameter naming, documenting the purpose of each test, and thoughtfully organizing what can become a large collection of test cases.
Clear Naming and Documentation
Descriptive parameter names make tests easier to understand. Instead of generic names like p1 or p2, use names that reflect the parameter's role, such as valid_email or invalid_password. For example:
@pytest.mark.parametrize("email, is_valid", [("test@example.com", True), ("test", False)]) def test_email_validation(email, is_valid):
... test logic ...
Including docstrings within your test functions should also be standard practice. Clearly explain the test's goal and the expected outcome for each set of parameters. Consider integrating with platforms like employee training software to manage and source larger datasets for your tests.
Organizing Large Test Suites
As your project expands, so will your tests. Organize them into logical groups within your directory structure. Consider grouping by feature, module, or test type. This simplifies locating and running specific sets of tests, making maintenance easier and improving team collaboration.
Handling Test Failures Effectively
Failures in parameterized tests require specific debugging strategies. Logging within your test functions provides valuable information about variable states and the execution flow for each parameter set.
Custom test reports, designed specifically for parameterized testing, can further improve debugging. These reports could group failures by parameter, revealing patterns and making it easier to identify the root cause of issues. Teams using parameterized testing have seen significant improvements in their testing process. Test creation time has been reduced by up to 70%, and test suite size has shrunk by approximately 40% while maintaining or even improving test coverage. More detailed statistics can be found here.
Migration Strategies for Existing Codebases
Adopting parameterized testing doesn't require a complete overhaul of your existing code. Start with a small, contained module. Convert repetitive tests into parameterized versions. This incremental approach provides immediate benefits without disrupting your entire workflow.
After demonstrating the value in one area, gradually expand to other sections of your codebase. Prioritize areas with the most duplicated test code for maximum impact. This targeted approach helps introduce the practice without overwhelming the team.
Intelligent Logging and Custom Reporting
Integrating robust logging into parameterized tests is critical. This lets you track code behavior under different input scenarios, speeding up debugging. Include detailed log messages within your test functions. Record variable values, intermediate calculations, and any unexpected behavior. You can create custom reports tailored to parameterized tests using tools like pytest-html. This generates customized HTML reports that summarize test results, providing a clear view of successes and failures for each parameter set.
Debugging Techniques for Parameterized Contexts
Debugging failures in parameterized tests requires a slightly different approach than debugging standard tests. Utilize debugging tools like Python's built-in pdb (Python Debugger) or IDE debuggers to step through the code execution for each parameter set. Setting breakpoints and inspecting variable values at each step helps pinpoint the exact conditions causing a failure.
By implementing these strategies, you can transform your parameterized tests from potentially fragile scripts into robust and maintainable assets, contributing to a more stable and reliable development process. Investing time in proper test maintenance ensures long-term value. Consider tools like Mergify's CI Insights to streamline your testing workflow, identify bottlenecks, and gain actionable feedback for optimizing your CI process.
Real Teams, Real Results: Parameterized Testing in Action
Seeing how others successfully implement a technique can be incredibly insightful. This section explores how parameterized testing, specifically with Python, has benefited teams across various fields. From web development and data science to API services and large enterprise applications, we'll examine real-world examples of how these tests have solved specific testing challenges.
Open-Source Success Stories
Open-source projects often face limited resources. Parameterized testing offers a way to maximize quality with minimal developer time. For example, several open-source Python libraries use parameterized testing to ensure code quality across various Python versions and operating systems. This approach enables thorough testing with fewer test functions, optimizing contributor efforts. These tests cover different input combinations, edge cases, and boundary conditions, which are crucial for maintaining stability in projects with diverse user bases.
Enterprise-Scale Parameterized Testing
Large enterprise applications require testing at a different scale. One financial institution uses parameterized tests in Python to validate trading algorithms across various market scenarios and historical data. These automated tests significantly reduce the risk of deploying faulty code into production, protecting the company from potential financial losses. This level of automated testing is essential for managing the complexity and risk associated with large, mission-critical applications.
The data-driven nature of parameterized tests helps uncover edge cases that might be missed in manually written tests. Projects have reported a boost in defect detection efficiency, with some teams achieving a 30% increase in early bug detection during unit testing. This improvement is particularly evident when running parameterized tests across hundreds or thousands of input combinations, common in large-scale software deployments. Additionally, the ability to stack parameters in Pytest allows for combinatorial testing scenarios. This creates hundreds of test cases programmatically from just a few parameters and datasets, exponentially expanding the scope of automated testing. Find more detailed statistics here.
Startup Agility With Parameterized Tests
Fast-growing startups need efficient, scalable testing. One successful health-tech startup uses parameterized tests in Python for its API. As they add new endpoints and features, their existing parameterized tests adapt to new scenarios by simply adding more data to the test inputs. This maintains high test coverage without constant test rewriting, saving valuable developer time and ensuring a quick time to market. This flexible approach is critical for startups adapting to rapid changes and evolving product requirements.
Measurable Results: Improved Efficiency and Quality
Across these diverse applications, parameterized tests demonstrate tangible benefits. Teams report significant reductions in test code and development time. One team observed a 40% reduction in their test suite size after adopting parameterized testing. This efficiency gain allows for more thorough testing, leading to earlier defect detection and fewer production issues. Faster feedback loops also improve collaboration between developers and testers, contributing to higher overall software quality.
Streamline your team's testing workflow and unlock the full potential of parameterized testing with Mergify. Mergify's intelligent merge queue and automated merge strategies free up developer time, allowing your team to focus on building high-quality software. Its CI Insights feature provides valuable data on test performance and identifies bottlenecks, further enhancing your testing efficiency and helping you achieve even better results with parameterized tests.