How NOT to use Redis


It's not a secret that we are fans of Redis. We've been leveraging it since day one at Mergify to store various volatile data. It's fast, robust, and easily scalable.
Six months ago, we introduced speculative checks support for our merge queue. We chose a simple data structure to store the extra information we needed to handle this feature, where each merge queue would have its own set of Redis keys.
🔥 Where things started to burn
After a few weeks, our users started to experience unexpected latency processing their pull requests. Our engine would process their pull request rules after a longer delay than expected.
The monitoring also shows some impressive peaks in processing latency:
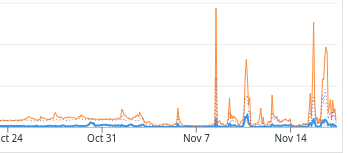
We started to look at the flux of events we received from GitHub, and after some digging, we began to distinguish some patterns.
🧐 Looking for the source
As we're taking our monitoring seriously, we're leveraging Datadog APM to audit our applications and get insight into their behavior.
If there's one thing you learn by using application monitoring, it is that you have no clue how your application behaves when reality hits it.
Looking at the average processing time for pull requests didn't look very good, as you can see below:
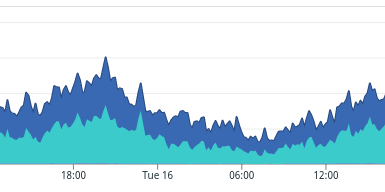
Knowing that the GitHub API calls (dark blue) are supposedly the slower action executed by the engine, we were surprised by seeing a lot of untracked time (the cyan area). In theory, we should mostly see dark blue on this graph.
More than surprised, we were lost because we had no way to dig into the cyan part of the graph without further instrumentation.
However, we already knew that we were not getting insight into Redis latency because we were using a Redis library (yaaredis) unsupported by Datadog.
Don't forget; we're always one step ahead. Therefore, before this whole investigation even started, we already worked with the Datadog team to add support for our Redis library in their tracer.
Once the code was merged and released, we upgraded our tracer and saw a third color: purple.
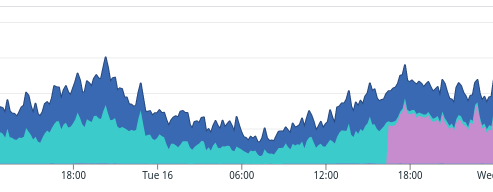
This made the problem way more apparent: the engine spent more time doing Redis I/O on a nearby server than calling the distant GitHub API.
Drilling down on a few traces, the culprit was easy to find: most of the commands we were sending to Redis were SCAN commands.

The engine would have to multiple SCAN to iterate over all the Redis database keys, each iteration taking tens of milliseconds.
The SCAN usage made sense. The data layout for the latest merge queue feature was simple: each merge queue had its own set of Redis keys. The engine would use the Redis SCAN command to list the merge queues as needed. However, we didn't plan for so many SCAN commands being run and taking so much time.
A quick check of the database size showed 500,000 keys.
😱
We knew that SCAN had many drawbacks when used on databases with a lot of keys. However, we also knew our database didn't have a lot of keys, and we were not expecting the number of keys to grow to such a high number.
⏳ When did this start?
Cross-referencing the type of the stored keys with the recently merged commits, we identified some code that started to cache new data about pull requests into Redis.
The newly added keys had an expiration delay, and we never expected their usage to grow that large — but they did, and they started to impact the latency of code that used the SCAN command.
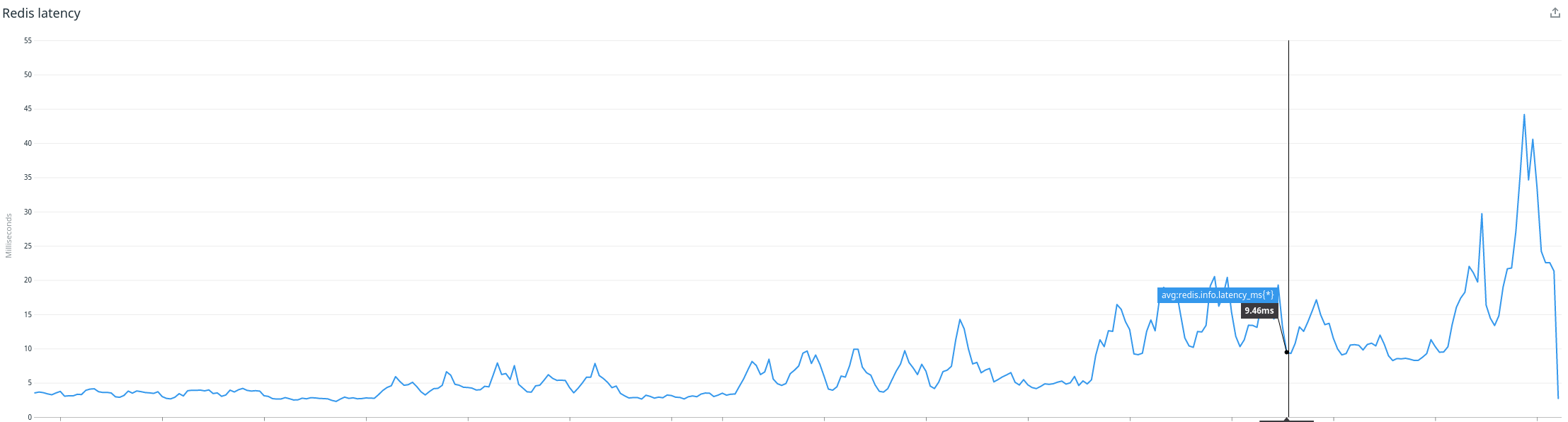
The Redis latency started to grow, drifting from a couple of milliseconds to 10x that.
🦾 The Master Plan
It became evident that our lazy approach of storing keys into the root of the Redis database was doomed to fail. We devised a plan where we would:
- group some of the keys into Redis hashes so we could instead leverage
HSCANthanSCAN, limiting the iteration scope; - move some keys to a different database.
The more urgent and impactful item being the first one, we implemented it first and are delighted with the result.
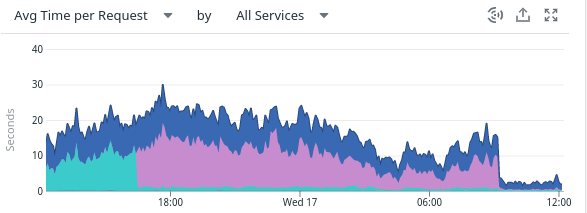
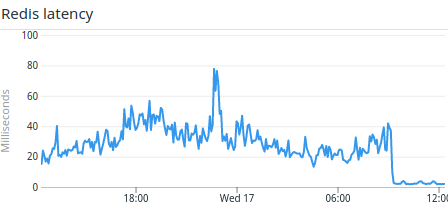
The Redis latency dropped back to normal as we deployed the new implementation, and the peak in pull request evaluation latency has vanished! 🎉