How to Actually Use DORA Metrics in CI (Without the Bullsh*t)


DORA metrics have become a staple in the world of software engineering management. Initially popularized by the "Accelerate" book and Google's State of DevOps reports, they've become a kind of north star for measuring engineering efficiency. You'll find them referenced in strategy decks, team retrospectives, and increasingly in investor memos too.
They're meant to represent how well your engineering organization is delivering software:
- Lead time for changes: How quickly do we get code from commit to production?
- Deployment frequency: How often do we actually ship?
- Change failure rate: How often does shipping break things?
- Time to restore service: How fast can we recover when things go wrong?
These metrics make intuitive sense. They're easy to explain. They feel actionable. But here's the truth: in most teams, they're not.
They either get treated like abstract KPIs that live on a dashboard and are never looked at again, or worse, they become something that gets tracked for the sake of tracking, with no apparent connection to how work happens on the ground.
What gets lost is this: every DORA metric is deeply tied to your CI pipeline.
CI is where DORA metrics actually live
The idea behind DORA is to measure delivery performance, not just code quality or output volume, but how fast and safely ideas can be turned into reality.
But almost every step that impacts DORA happens in and around your CI system.
Let's start with lead time for changes. On paper, this is "commit to prod." In reality, it's usually:
commit → CI runs → PR waits → CI reruns → finally merges → deploy pipeline → manual approval → prod
The majority of those steps are either directly owned or blocked by CI. If your pipeline is slow, flaky, or requires manual intervention, your lead time suffers. Most teams don't need to "go faster"—they need to stop wasting time inside CI.
Deployment frequency has similar constraints. We like to consider it a cultural trait: "We deploy often because we move fast." But in practice, teams deploy often when the pipeline is trustworthy. A flaky or noisy CI pipeline teaches teams to wait, delay, stack up PRs, and batch deploy—all of which erode frequency. If it takes 40 minutes to build and deploy every PR, nobody's going to ship small commits.
Change failure rate is where CI quality really shows up. If your deploys are green but things still break in production, it usually means your tests aren't catching the right things. And often, the issue isn’t that you don't have tests — it's that CI is quietly skipping them. Flaky jobs that pass on retry, tests that are too slow to run on every commit, and don't mock-based tests that don't reflect production behavior. CI can mask these failures just as easily as it can prevent them.
And then there's time to restore service. When something breaks, CI becomes either your best friend or your worst enemy. A slow, noisy, or unclear pipeline delays the fix just as much as it delays the deployment, especially when a flaky test failure means you can't merge the fix or when rerunning tests becomes a guessing game instead of a confidence boost.
In all of these cases, what we label as a "DORA metric" is actually a CI bottleneck in disguise.
DORA isn't about dashboards — it's about friction
What we've seen — both in our own work and with the teams we talk to — is that DORA only becomes useful when it's tied back to friction.
When a team's lead time is too long, it's rarely because devs are typing slowly. It's usually because they're rerunning tests. Because CI didn't pick up the push. Because the merge queue is blocked. Because nobody wants to be the person who breaks staging before the weekend.

When deployments are infrequent, it's often because CI isn't trusted, not because people are slow, but because they don't feel safe.
So if you're serious about using DORA to improve delivery, the best place to look isn't a Google Sheet. It's your .yml files. Your job logs. Your retry patterns. The Slack thread where someone says:
"Ugh, it flaked again."
Making DORA actionable means surfacing invisible costs
DORA often feels disconnected because most of the things that affect it are invisible. Reruns don't show up in a metric, queue times don't get reviewed in retros, and test flakes don't get tracked unless someone's really motivated.
And yet, this is where delivery performance lives.
What we need isn't just better DORA metrics — it's better observability into CI itself. Not just "did the pipeline pass," but "how many times did it need to be retried?", "Which jobs flake the most?", "Which jobs are getting slower?" "Which jobs are silently absorbing 3 hours of team time weekly?"
When you start asking those questions, DORA stops being theoretical. It becomes a tool to debug your delivery process, not just report on it.
Tracking DORA Metrics
DORA metrics are worth tracking — but only if you're ready to trace them back to the system that actually drives them: your CI. If you don't, they'll stay abstract. And they'll stay broken.
Once you do, they become something a lot more useful: a roadmap to better engineering.
Curious what your CI is hiding from you?
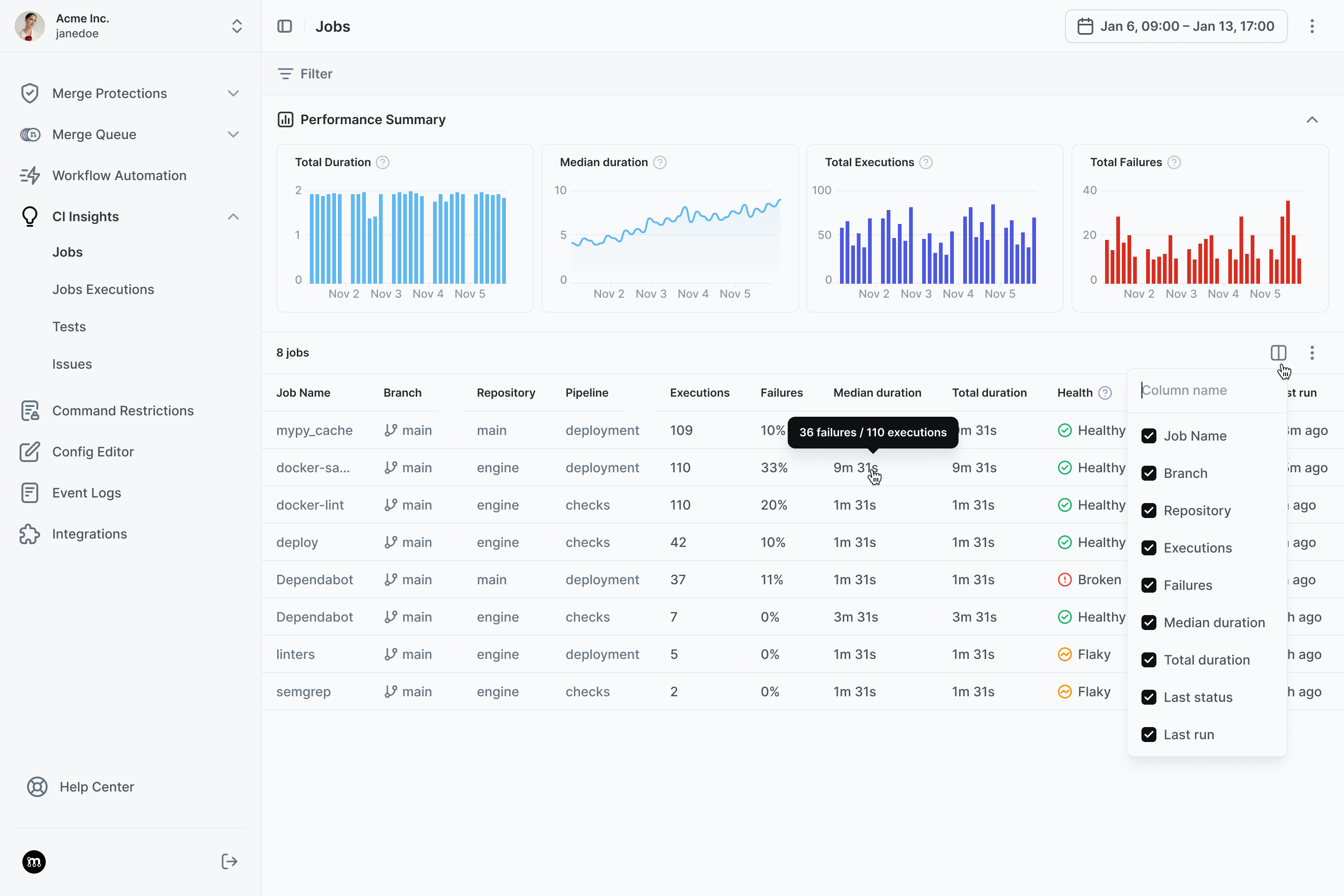
We’re building CI Insights to help teams see the flakiness, reruns, and delays that quietly shape their DORA metrics.
👉 Check out the beta — and help us build the future of CI observability.