GitHub's Merge Queue Isn't Enough for Large Teams


Why large engineering orgs quickly hit the limits of GitHub's queue — and what they actually need.
Over the last couple of years, GitHub has been rolling out its own merge queue feature. It's a welcome recognition of a real problem: teams need better ways to manage the complexity of merging changes into main without breaking builds, introducing regressions, or wasting CI cycles.
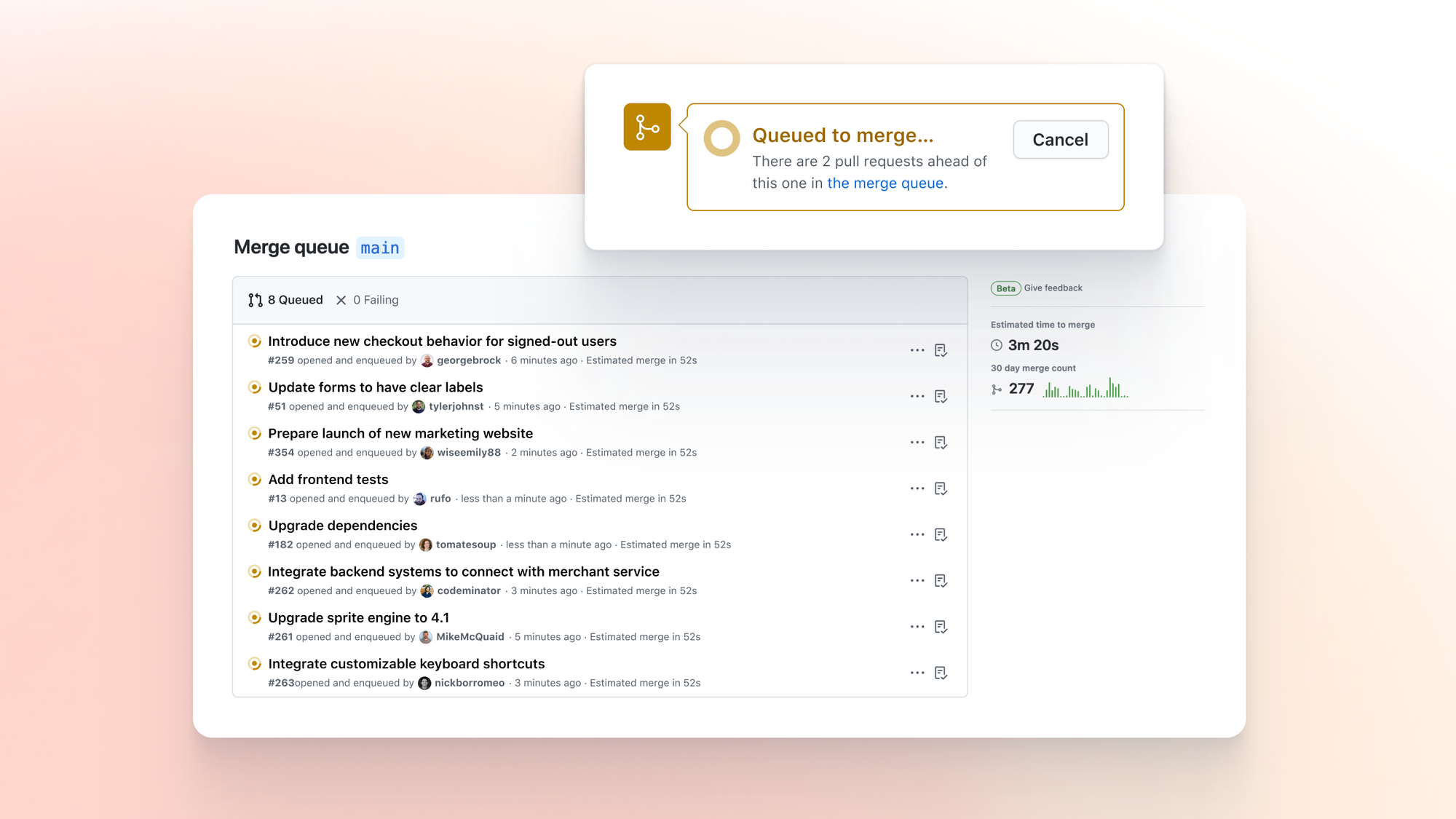
But for many engineering organizations, GitHub's queue just isn't enough.
Over the last months, we spoke with a few large companies that gave it a real try. The result? It failed to meet their needs. Their workflows were too complex, their scale too real, and the limitations of GitHub's merge queue showed up fast.
Here's why.
1. No support for batching
GitHub merges PRs one by one. That might work for small teams or low-frequency repositories. But as soon as your team is pushing tens or hundreds of PRs per day, this becomes a bottleneck.
Mergify supports batching: it groups PRs together, tests them as a unit, and merges them atomically if the build passes. This saves CI time, catches integration issues earlier, and reduces queue churn.
Without batching, you’re stuck in line.

2. No bisect-on-failure strategy
What happens when a batch fails?
At Mergify, we built an intelligent bisect-on-failure strategy. If a batch of PRs fails CI, Mergify will split the batch automatically and re-test, isolating the problematic PR. That means faster merges for the rest of the batch and fewer manual retries.
For high-volume teams, this is a must-have.
3. No priorities, no flexibility
All PRs are treated equally in GitHub's queue. But real teams don't work like that.
With Mergify, you can assign merge priorities. Hotfixes can jump the line. Low-priority or experimental changes can be delayed. And you can customize conditions and workflows across repos and teams.
Merge logic isn't one-size-fits-all. Mergify reflects that.
4. No CI intelligence
GitHub's queue is blind to what happens inside CI. If your tests are flaky, slow, or constantly retrying, the queue won't notice. You'll just feel the pain in delays and confusion.
Mergify is building CI Insights. It's a full observability layer for your merge pipeline:
- Detect flaky jobs
- Track retry loops
- Analyze job duration trends
- Alert on anomalies
It's not just about merging safely. It's about understanding why you're not.
5. No incident handling or deployment freeze capabilities
Production is on fire. CI is unstable. What do you do?
With Mergify, teams can pause the merge queue and freeze deployments instantly. You can:
- Define scheduled or manual freeze windows
- Automatically block merges when incidents occur
- Resume operations safely once things are back under control
GitHub's queue does not have a built-in mechanism for handling incidents or CI instability, which is a non-starter for any team doing continuous delivery.
6. Most teams don't even need a queue. They need rebase-before-merge.
Ironically, many teams trying GitHub's merge queue don't even need one.
What they need is a way to ensure that code is tested on top of main before it merges. That's exactly what rebase-before-merge does — and Mergify workflow automation supports it out of the box, with less overhead than a queue.
So while GitHub is now following the merge queue path we pioneered five years ago, we're already building what real teams need next.
If your merge queue doesn’t adapt to your team, it’s not helping you ship.
Mergify has been battle-tested by thousands of teams over the past 5 years, from early startups to large orgs with massive CI pipelines.
We know what breaks, what flakes, and what slows everything down.
That’s why we built:
- A merge queue that supports batching, priorities, bisecting, and freeze handling
- A rebase-before-merge strategy for teams that need simplicity
- A CI observability layer that sees what your green checks are hiding
Want to see how it all works? Book a demo or try it free today.