Flaky Test Detection Mastery: Your CI Pipeline Success Guide

The Hidden Pipeline Killer You're Probably Ignoring
Let's be honest, most engineering teams have them: those "occasional" test failures that seem small but secretly wreak havoc on your development velocity. I've chatted with so many frustrated DevOps engineers who describe how these little glitches turn into massive time sinks. That test that "only fails sometimes" is a hidden productivity killer, impacting the whole team.
It's not just the wasted time spent rerunning tests. It's the mental fatigue. Developers start to lose faith in the test suite, and it becomes a "boy who cried wolf" situation. Genuine bugs get mistaken for flakes, eroding the credibility of the whole testing process. This lack of confidence spills over into deployment decisions. Nobody wants to ship code they're unsure about, which leads to delays and missed deadlines. Ultimately, this hits the bottom line – a financial impact that often goes unnoticed by executives.
Flaky tests are a real pain in software development, especially in automated testing. The World Quality Report by Capgemini states that roughly 50% of the time spent on automation goes toward fixing broken tests, many of which are flaky. That's a huge drain on resources. Something as simple as network variability can cause intermittent test failures. Want more insights on flaky tests? Check this out.
Recognizing the Warning Signs
So, how can you tell if flaky tests are becoming a problem? One clear sign is the "rerun" reflex. If your team constantly reruns tests without digging into why they failed in the first place, you have a problem. Another red flag? Low developer morale. When engineers don't trust their tools, motivation plummets.
Finally, examine your CI/CD pipeline. Are builds failing intermittently without a clear reason? Are releases constantly delayed because of unstable tests? These are all symptoms of a flaky test infestation. For a more in-depth look at this, check out this guide on flaky test detection and prevention.
Learn to spot these warning signs before flaky tests spiral into a full-blown crisis that drains your team's productivity and budget. Proactively addressing this "hidden killer" is crucial for a healthy and efficient development pipeline.
Your Flaky Test Detection Toolkit (What Actually Works)
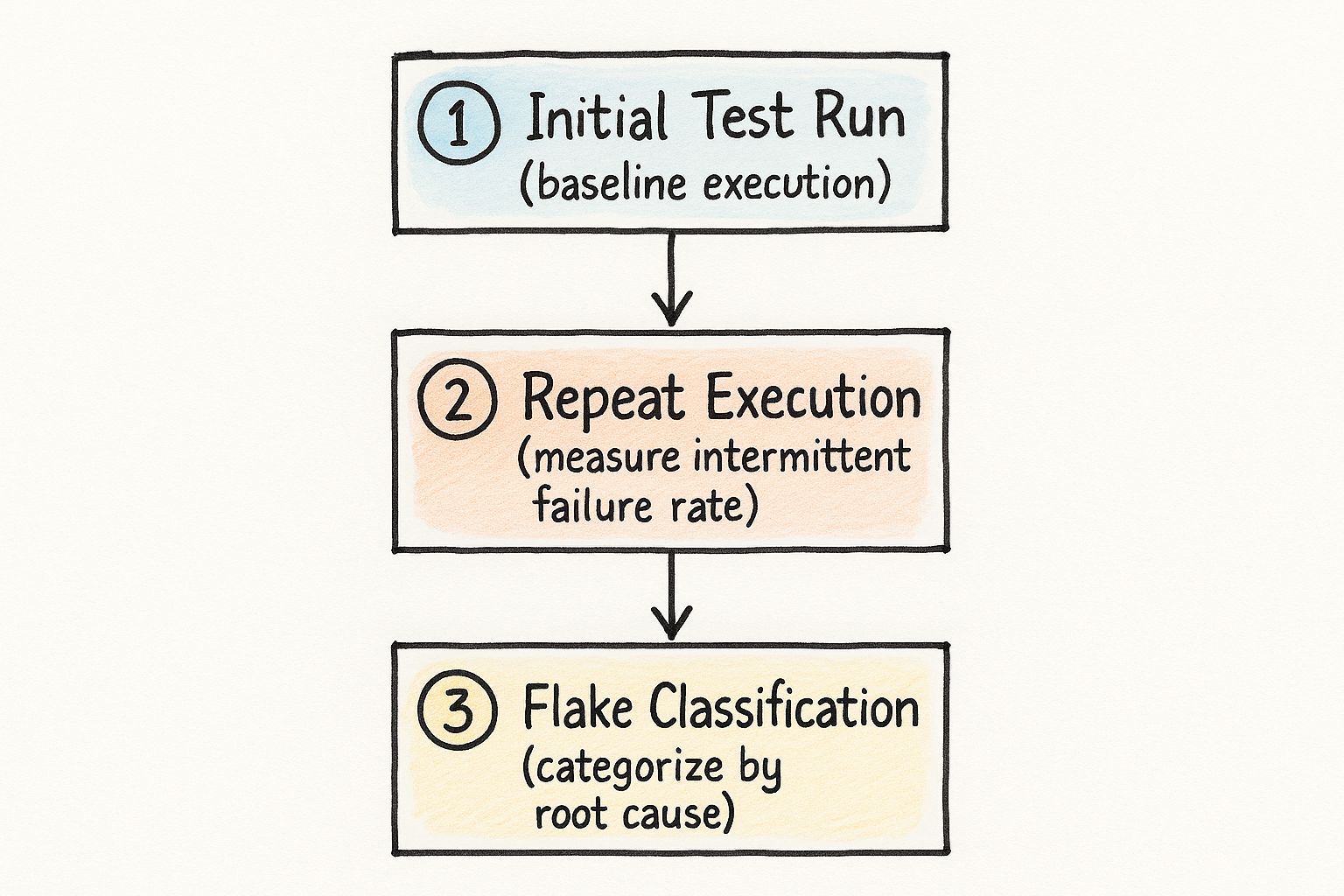
This infographic shows the core of flaky test detection: a baseline run, repeated test executions, and classifying the flakes. Notice how it focuses on finding patterns instead of chasing individual failures. That's key to identifying real flaky tests and fixing the root causes.
Now, let's talk tools. Choosing the right ones can be a headache. Marketing hype makes it hard to tell what's actually useful. Believe me, I've spent hours wading through tools promising the moon. Based on my experience and chats with other DevOps folks, here’s what truly matters.
Open-Source Gems: Value Without the Vendor Lock-in
Open-source tools are awesome, especially if budget's tight. I’ve had great success with Jest. Its retry feature immediately flags flaky tests during development. Pair that with a reporting tool like JUnit, and you've got a solid tracking system. Another tool worth checking out is Playwright. Its test runner and debugging features are invaluable for finding the root cause of flaky tests. Even free tools take time to integrate, so start small and focus on what benefits your team.
Configuration Strategies: Finding the Sweet Spot
One common trap is overly sensitive configurations. Teams get flooded with false positives, leading to alert fatigue – which nobody wants. Flaky test detection shouldn't create more work. The trick is balance. Focus on tests that consistently flip-flop between passing and failing without code changes. I recommend a failure threshold of 2-3 consecutive failures before flagging a test as potentially flaky. This helps filter out the noise and focus on real problems.
Monitoring Approaches: From Reactive to Proactive
Many teams start by investigating flaky tests after a broken build. It's a start, but it feels like playing whack-a-mole. Aim for a proactive approach. Continuously monitor test results. Visualize trends. This lets you spot patterns and fix issues before they disrupt everything.
To help you choose the right tool, I've put together this comparison table:
Flaky Test Detection Tools Comparison A comprehensive comparison of popular tools for detecting flaky tests, including features, pricing, and integration capabilities.
| Tool Name | Key Features | Integration Options | Best For | Pricing Model |
|---|---|---|---|---|
| Jest | Built-in retry functionality, snapshot testing | CI/CD pipelines, reporting tools | JavaScript testing | Open Source |
| JUnit | Detailed test reporting, assertion framework | Various IDEs and build tools | Java testing | Open Source |
| Playwright | Cross-browser testing, robust test runner | CI/CD integration, debugging tools | End-to-end testing | Open Source |
This table provides a quick glance at some popular options, highlighting their strengths and integration possibilities. Remember to factor in your specific project needs when making your decision.
With the right tools and configuration, flaky test detection becomes a source of continuous improvement instead of a constant headache. Your CI/CD pipeline (and your team) will be much happier.
Making Sense of Test Patterns With Smart Analytics
This dashboard is a perfect example of how visualizing test results can bring real clarity. Imagine watching trends appear over time – you're suddenly empowered to fix problems before they become major headaches. We're not just reacting to failures; we're predicting and preventing them. This is the power of smart analytics, turning raw test data into actionable insights. If you're new to some of these concepts, a quick look at this guide on AI Chatbot Terminology might be useful.
Identifying Flaky Behavior With Pattern Recognition
Think of debugging flaky tests like detective work. Instead of chasing individual failures, you're hunting for recurring patterns. A test failing intermittently without any code changes? That's a major red flag. Effective flaky test detection is all about spotting these patterns before they derail your releases. This means diving into your historical test data to uncover trends and identify those suspiciously inconsistent tests.
Calculating Meaningful Failure Rates
Simply counting failures doesn’t give you the full picture. A test that fails once out of ten runs is a very different beast than one that fails nine times out of ten. Calculating failure rates and understanding their statistical significance is key. This involves analyzing the mean, median, and quartiles of your failure distribution. I once came across a study that analyzed 1,092 test cases and found that 357 exhibited flaky behavior, with a mean flake rate of 0.30% for those flaky tests. You can find more details about the study here. It really highlighted how these seemingly small issues can significantly impact the whole pipeline.
Setting Actionable Thresholds
Getting alerted for every single failure is just noise; it leads to alert fatigue. You need to define thresholds based on your risk tolerance and how critical each test is. Maybe that’s setting an acceptable failure rate or requiring a minimum number of consecutive failures before an alert triggers. The goal isn't to eliminate all failures, but to manage them strategically.
Statistical Metrics for Flaky Test Detection
To help you get started, I’ve compiled some key metrics you should track. The table below provides a quick overview of how to calculate them, recommended thresholds, and the actions you should take when those thresholds are breached.
Flaky Test Statistical Metrics: Key statistical measurements and thresholds for effective flaky test detection and monitoring.
| Metric | Calculation Method | Recommended Threshold | Action Required |
|---|---|---|---|
| Failure Rate | (Number of Failures) / (Total Test Runs) | > 1% | Investigate and fix |
| Consecutive Failures | Number of times a test fails in a row | > 3 | Quarantine the test |
| Intermittent Rate | (Number of times passing state changes) / (Total Test Runs) | > 5% | Investigate test dependencies |
These metrics help you quantify flakiness and prioritize your efforts on the tests that need the most attention. By combining pattern recognition with statistical analysis, you can move from reactive firefighting to proactive prevention, building more reliable test suites and shipping code with confidence.
Seamless CI Integration Without the Headaches
Integrating flaky test detection into your CI pipeline shouldn't be a painful experience. It should make your life easier, not harder. I've helped teams successfully integrate these systems into platforms like Jenkins, GitHub Actions, and GitLab CI, and I'm happy to share some tips from the trenches.
Gradual Rollout: Managing the Alert Flood
Brace yourself: when you first switch on flaky test detection, expect a deluge of alerts. Don't freak out! It's completely normal. Start small, maybe with a handful of mission-critical tests or a single service. This controlled approach lets you tweak settings and get a feel for the system without drowning in notifications. As your team gets comfortable, gradually broaden the scope. Think of it like slowly turning up the volume – you adjust to the increased signal without being overwhelmed. Resources on continuous integration best practices, like this guide from Mergify, can be super helpful during this phase.
Configuration: Adapting to Your Workflow
Flaky test detection isn't one-size-fits-all. You need to tailor the configuration to your team's specific workflow. Consider how often you build, the size of your test suite, and your comfort level with risk. For example, a team deploying several times a day will likely have different alert thresholds than a team releasing weekly. Don't be afraid to experiment until you find the sweet spot between catching genuine flakes and minimizing noise.
Feedback Loops: Refining Accuracy Over Time
Setting up flaky test detection isn't a "set it and forget it" kind of deal. It’s an ongoing process of refinement. Establish feedback loops to continually improve the accuracy of your system. Keep track of false positives. Dive into why they're happening. Then, adjust your configuration accordingly. This active management will make your system smarter and more dependable over time. Interestingly, studies show that developers sometimes think they've fixed flaky tests when they haven’t actually reduced the flakiness. This research on the lifecycle of flaky tests offers some valuable insights. It really underscores the importance of careful analysis and constant monitoring.
Building Trust Through Transparency
Getting developers on board is critical. Make sure your flaky test detection system is transparent. Share the data. Explain the metrics. Show them how it benefits them. This builds trust and encourages adoption. When developers understand why a test is flagged as flaky, they're much more likely to address it. Here's a screenshot of GitHub Actions as an example:
The clean interface for setting up workflows and integrating with testing tools makes it easy to see how flaky test detection fits into the existing CI process. This visibility and seamless integration lead to smoother adoption and greater developer confidence. By empowering developers with clear insights and workflows, you create a system they'll actually want to use, rather than one they resist.
Alert Systems That Drive Action (Not Eye Rolls)

This Slack notification shows how slick it is to pipe flaky test alerts right into your team’s chat. See how clean and clear that formatting is? A direct link to the failing test means developers can jump right in without wading through endless logs. Effective alerts equal faster fixes and fewer headaches.
Let's be honest, alert fatigue is real. I’ve personally seen so many monitoring systems turn into useless noise-makers because they’re constantly screaming about everything. Flaky test alerts are particularly bad for this. If your team starts hitting “mute” on those notifications, you've already lost. So how do you build an alert system that actually helps?
Designing Effective Escalation Paths
Blasting generic alerts to everyone is a recipe for chaos. What you really need is an escalation path tailored to your team. Maybe a first-level alert goes to the developer who last touched the code. If it’s still an issue, then bump it up to a senior engineer or the on-call team. One less headache-inducing thing to worry about is tying your flaky test detection into your CI tooling with some smooth automation. There are some really helpful tips in this guide on Jira workflow automation if you're using Jira. A good escalation path makes sure the right people are in the loop at the right time.
Actionable Notification Formats
Alerts need context. “Test failed” is about as useful as a chocolate teapot. Include the test name, the actual error message, the commit that triggered it, and a link directly to the logs. The goal? Make it so developers can diagnose and fix the problem right then and there. Rich, informative alerts save precious debugging time.
Response Protocols That Actually Work
You've got to have clear response protocols. Who owns each alert level? How long should it take to address it? Writing these protocols down helps keep things consistent and prevents confusion when things get hairy. Clear protocols translate alerts into action.
Building Trust in Alert Accuracy
If your alerts are wrong all the time, they’ll get ignored. You have to build confidence in your flaky test detection. One way to do that is by tracking false positives. If a test keeps getting flagged as flaky but it’s actually fine, dig in and tweak your detection settings. Over time, this constant refinement builds trust and makes sure alerts are treated seriously, not just dismissed as noise. Accurate alerts mean a more responsive and efficient team.
This whole process of tweaking and improving your alerts is essential. By focusing on clear escalation, informative notifications, defined response protocols, and constantly improving accuracy, you build a system that encourages action, not frustration. Your team will thank you for less noise and more time to focus on what really matters: building great software.
Measuring What Matters (Beyond the Obvious Metrics)
So, you've set up a system to catch those pesky flaky tests. Fantastic! But now you've got to prove it was worth the time and effort. Just showing off the new tools isn't enough. You need to show a real impact on the business, not just a technical win. Picking the right metrics is key here.
Focusing on Business Outcomes
Forget about “vanity metrics” like "number of flakes detected." Focus on what really matters to the business: reduced debugging time, improved developer confidence, faster release cycles, and even higher team morale. These are the things that matter to stakeholders and justify the investment. I remember one project where we were absolutely drowning in flaky tests. We implemented a solid detection system, and suddenly we had a 20% decrease in debugging time. That freed up the developers to work on new features! That kind of improvement really speaks for itself.
Building Compelling Dashboards
Data is useless if no one can understand it. Create dashboards that tell a story. Visualize trends in flaky test frequency, highlight the reduction in debugging effort, and showcase how much faster your release cycles are. A good dashboard turns raw data into a compelling story that even non-technical people can understand. It’s about showing value, not just showing numbers.
Establishing Baselines and Leading Indicators
You can’t measure improvement without knowing where you started. Track your current metrics before making any changes. This gives you a benchmark to compare your progress against. Also, look for leading indicators that tell you how well your detection system is working. For example, a drop in false positives probably means your system is getting smarter over time.
Practical Frameworks for ROI and Communication
Figuring out the ROI for flaky test detection might seem tricky, but it is possible. Put a number on the time saved on debugging. Translate faster release cycles into increased revenue. And don't forget to factor in the improved team morale and productivity. Then, explain these results to management in clear, concise language. Focus on business value, not technical jargon. For example, instead of saying "we reduced flaky tests by 15%," try "we got new features to market 10% faster." That kind of language resonates much more effectively with business leaders. Think of it as translating engineer-speak into executive-speak.
By focusing on the right metrics and communicating effectively, you can show the real value of your flaky test detection system. This not only justifies the initial investment but also helps you secure ongoing support for making it even better.
Your Practical Implementation Roadmap
So, we've talked a lot about flaky test detection. Now, let's get down to brass tacks and create a plan you can actually use today. Forget theoretical fluff; we'll focus on actionable steps based on where your CI currently stands, setting realistic goals, and providing checklists to ensure you don't miss any critical details. Every piece of advice here comes with clear success metrics and potential pitfalls to watch out for, giving you the confidence to implement your strategy effectively.
Prioritizing for Maximum Impact
Your starting point really depends on your current CI setup. If you're just starting out, focus on the basics of flaky test detection tooling. Integrating something like Jest's retry functionality is a great first step, allowing you to begin tracking those pesky intermittent failures. For those of you with more mature CI pipelines, you can dive into more sophisticated areas like smart analytics and automated alerting. I found this guide on mastering flaky tests super helpful when I was setting up our system. Remember, small, incremental changes are more sustainable than trying to boil the ocean.
Realistic Timelines: No Overnight Miracles
Let's be honest, implementing flaky test detection takes time. Don't expect to wave a magic wand and fix everything in a week. For basic tooling, a 2-4 week rollout is a reasonable timeframe. More advanced systems? Think 1-2 months. This accounts for integration time, getting your team up to speed, and, let's face it, the inevitable hiccups along the way. Think marathon, not sprint.
Checklists for Success: Don't Miss a Thing
Here's a handy checklist to keep you on the right path:
- Tool Selection: Make sure the tools you choose fit both your tech stack and your budget. No point in buying a Ferrari when a reliable pickup truck will do the job.
- Integration: Don't just shove it in and hope for the best. Plan your CI integration methodically, starting with a small group of tests.
- Alerting: Set clear alert thresholds and escalation paths. Trust me, alert fatigue is real.
- Metrics: Establish baseline metrics. This allows you to measure progress and demonstrate the value of your work (ROI).
- Team Buy-in: Get your team involved early. Their input and support are essential for a smooth adoption process.
Pitfalls to Avoid: Learning From Others' Mistakes
I've seen a few common traps that you can easily avoid:
- Overly Sensitive Alerting: If your team is bombarded with alerts, they'll start ignoring them – including the important ones.
- Ignoring False Positives: False positives erode trust in the system. Address them promptly.
- Lack of Team Communication: Keep everyone in the loop throughout the process. Transparency is key.
By following these guidelines and learning from the experiences of others (including my own missteps!), you can successfully implement flaky test detection and build a more dependable and efficient CI pipeline. Remember, it's a journey of continuous improvement, not a destination.
Ready to take control of your CI pipeline and finally banish those flaky tests? Check out how Mergify can help you achieve seamless code integration and a more stable development workflow.