Auto-Retry Is the Duct Tape of CI — Here’s Why We Need It


You push a PR. CI kicks off. Ten minutes later, red.
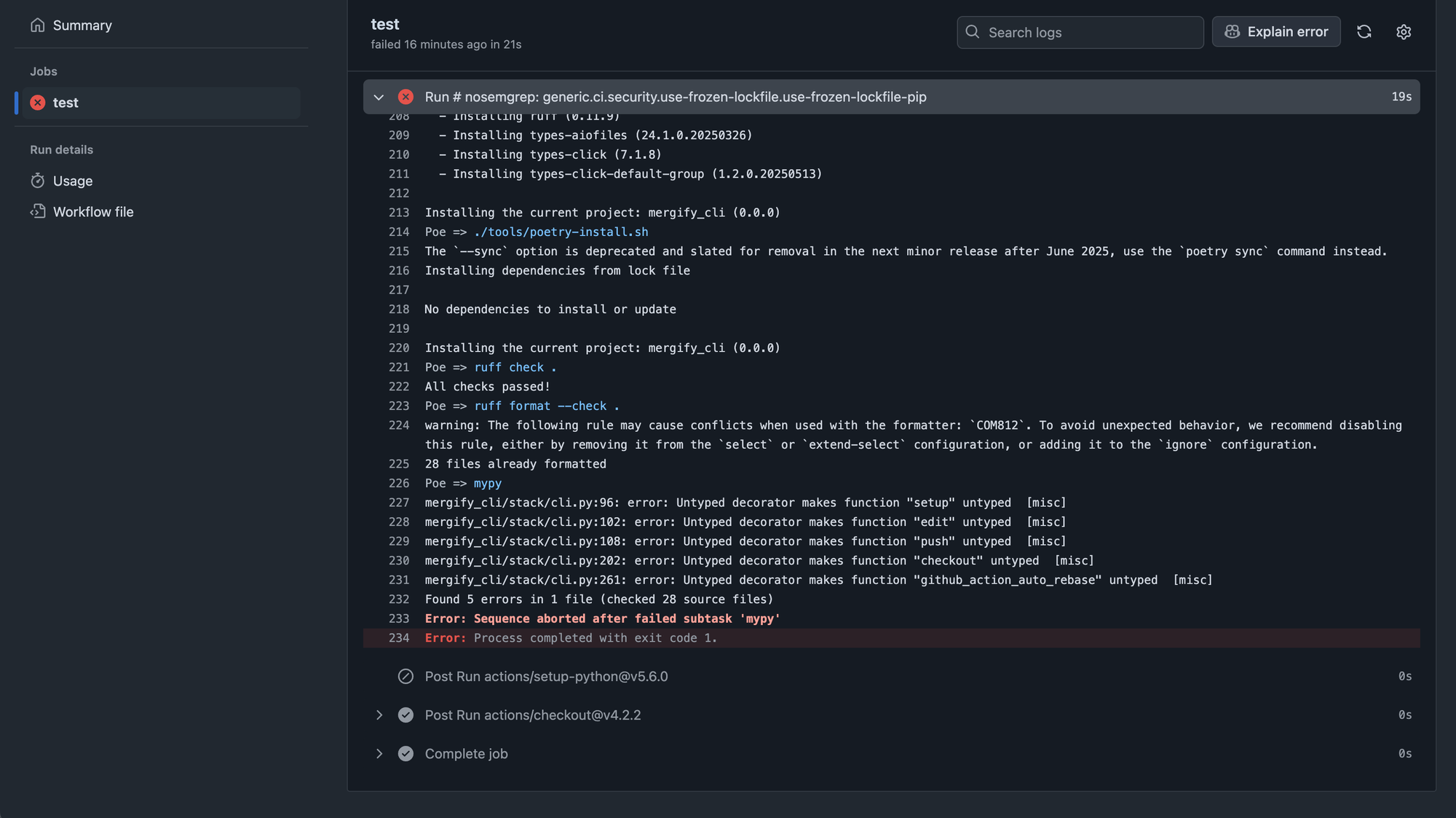
You check the logs.
It’s a test that fails every now and then — you’ve seen it flake before.
It times out, or throws a weird assertion. Maybe it’s infra. Maybe it’s racey. Maybe you don’t even care anymore.
You click “Retry.”
It passes. You merge. You move on.
The Next Day
The next day, someone else pings you.

“Hey, did your PR break this test? It’s failing for me now.”
You don’t know. It didn’t fail for you. At least not finally.
You just reran it until it turned green.
This is where a lot of teams end up with CI:
Half trust, half habit. A system that “works” — as long as you’re willing to babysit it.
Auto-retry is duct tape. And we all use it.
I’m not against auto-retry. In fact, I love it.
CI isn’t deterministic.
Jobs fail for reasons that have nothing to do with your code:
- Docker pull limits
- Cloud runner cold starts
- Network hiccups
- Flaky mocks
- “It passed locally”
¯\(ツ)/¯
Auto-retry keeps velocity up when CI would otherwise block shipping.
It saves hours.
It lets engineers focus on the code — not the randomness around it.
But duct tape works best when you know where it’s holding things together.
When retry is invisible, confidence erodes
I’ve seen teams where retry was the fix for everything.
“Just rerun it, it’s always like that.”
Builds fail, builds get retried, builds go green — and no one remembers to look back. It becomes normal.
We stop asking why jobs fail, because the fix is one click away.
We trust the green check, even when we know it’s masking something flaky.
The team’s confidence in CI drops. But so does the pressure to improve it.
That’s the quiet cost of auto-retry: it prevents disaster… and hides decay.
We built CI Insights to make this visible
When we built CI Insights, we didn’t want to replace your CI.
We wanted to show you what’s really going on inside it.
That’s why one of the first things we added was retry awareness.
CI Insights shows you:
- Which jobs pass after retry (flaky)
- How often each job flakes
- What your “retry recovery rate” looks like
- Which jobs eat up the most rerun time
- When your team is stuck in a silent feedback loop
It doesn’t stop jobs from failing.
But it tells you whether you’re fixing things… or just getting lucky.
Confidence isn’t just about test coverage
It’s about knowing that when CI says “green,” it means it.
And if it had to say “red” twice before that, someone should know.
CI Insights gives you a clear view of that — and lets you automate retry with context.
By job, by condition, by intent — not just “try again and pray.”
Want to know what your retry pattern really looks like?