On API Keys Best Practices


APIs are everywhere. They became ubiquitous over the last years and every startup building a product is now ordered to offer them. They became a major selling point for any SaaS business.
Engineering and product teams focus on the design of their API, from top to bottom, making sure they leverage the correct REST verbs or the latest GraphQL features.
However, there's an aspect of the API product that is often overlooked: authentication. The technical solutions for authenticating API users vary, and can be anything between JSON Web Tokens, OAuth 2.0, or API keys. Authentication more than often relies on credentials, and they are a keystone of any API service.
We spent a large amount of connecting APIs together over the last years, and we found a few (anti) patterns in authentication handling in API. We also designed our own API those last month, and implement our own API key system.
That gave us a good reason to share tips and best practice advice on implementing API keys.
Why API keys?
Authenticating an API user boils down to two basic needs:
- finding out who the user is;
- making sure the user is who they say they are.
The most common way of solving the issue is to assign a username to the user (which solves the who is the user question) and a password (which makes sure the answer to who is correct).
The drawbacks of using the login/password approach are multiple:
- The security of the password is entrusted to the user. As the #1 used password is still
123456, everybody can agree the user should not be trusted to pick a good password. - The login/password is unique per user, meaning it needs to be shared with all the tools that might need access to the API. Any problem with any of those tools means everything is compromised and password rotation is a nightmare.
- In most cases, if lost, the password can be used to hijack the account and change the password, locking out the account.
- The scope and the privileges provided by accessing the API with a username/password are not unlimited.
However, as it's very simple to put in place, many APIs started supporting authentication this way. For example, the GitHub API supported username/password authentication until GitHub decided to phase it out in 2019.
Years of security issues made this approach undesirable and less and less API support this and are using API keys instead.
Using API Keys
In order to fix those flaws, the next best thing is to use API keys. API keys have the same purpose as a username/password duo, except that they fix most of the issues it had:
- The key is generated by the API. This avoids poor choice by the users in terms of passwords.
- The API key is different from the username. Only the API can know the user a key belongs to.
- The API key does not leak the user password, making it impossible to lock out the user account if the API key is leaked.
- The API key privileges can be different and limited.
With all that, API keys keep the simplicity of the username/password approach as they consist of a simple string, making them as simple as a username/password to be used in any application.
Generating API Keys
As the application is responsible for generating API keys, it's time to do a good job of it. The idea is to generate opaque strings, that do not wear any meaning to the user or to a potential attacker.

They must be unique to identify the user and random to stay unguessable.
A good approach is to mix two different strings together: one for identifying the user (like a username) and one as a password. The first part makes it easy to lookup the key in your database, while the second one makes sure the key is correct (it's the secret part). For example, AWS uses an Access Key ID and a Secret Access Key to authenticate users.
Depending on the programming language and framework you use, they are multiple options. For example:
- In Python, you can use
secrets.hex_tokento generate secret tokens. Usesecrets.compare_digestto compare the generated API keys if they are stored in plain text and avoid timing attacks (they shouldn't be though, see below); - In Ruby, you could use
SecureRandom.urlsafe_base64to generate a random secret. You can useActiveSupport::SecurityUtils.secure_compareto compare keys if they are stored unencrypted (they shouldn't be though, see below). - In Java, use
SecureRandomto generate a secret API key. - (For other languages, feel free to leave a comment below and we'll add them to this list!)
Once you have generated those 2 pieces, you can store them in a database, using the first string as a identifier and the second one as a password. The latter should be encrypted as we'll see just after.
A good practice is to prefix your token with a string that makes sense. For example:
- GitHub prefixes the key like this:
ghu_XXX,ghp_XXXorgha_XXX. Each prefix means something, such as GitHub Personal or GitHub Application. This makes it easy to spot the key's service. - Stripe uses
sk_live_XXX,sk_test_XXX,pk_live_XXXorpk_test_XXX. The sk prefix designates the secret key, while the pk prefix indicates the key is public. - Mergify prefixes the keys with
mka_XXXfor its application key.
API Keys Lifecycle
Like any secret, API keys need to be rotated regularly. Any company implementing a thoughtful security policy needs to change its API keys routinely — usually once a year or on any security incident. This is part of best security practices and is commonly required by operation control frameworks, such as SOC 2, HIPAA, or ISO 27001.
As an API key provider, you need to provide some mechanisms to help your users in their duty:
- Allow multiple API keys, if the user wants to rotate its API Key without downtime it needs to be able to use at least two keys in parallel during a short time.
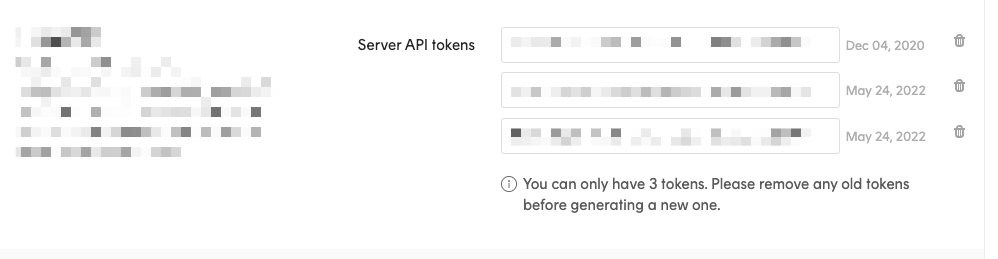
- Add a key expiration, the user can set it according to its secret rotation policy. When an API key is no more used, it will be revoked automatically if it misses being deleted.
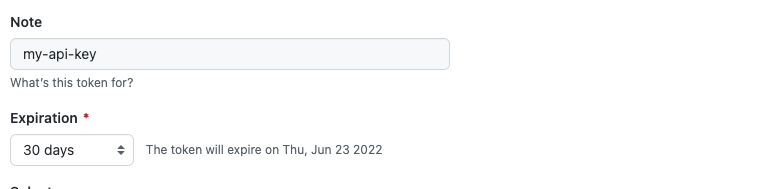
Storing API Keys
There are industry standards when it comes to storing secrets, such as API keys.
The main principles are:
- Encrypt your credentials at rest. Use an industry standard such as AES-256 to encrypt your volume.
- Encrypt your credentials in your database. While encryption at rest protect your token from physical robbery, having data encrypted during runtime makes sure that connecting to the database is not enough to exfiltrate your tokens. For token, the best method is to use a salted hash to store passwords.
- Encrypt your tokens in transit. Protocols such as TLS are now standard and you must make sure that tokens are encrypted while transiting from the client, to your server and the rest of your infrastructure. For example, make sure you use a TLS connection between your application and your database too.
This techniques should protect against most of the common threat:
- An attacker stealing a hard-drive would be defeated by rest and database encryption;
- An attacker connecting to the database would be defeated by database encryption;
- An attacker exploiting a bug in the application would be mostly defeated by database encryption;
- An attacker listening on the wire would be defeated by the in-transit encryption;
- An attacker accessing a database backup would be defeated by database encryption.
While this definitely does not cover all the security threats you might encounter, this is a solid basis that should be implemented no matter what.
Encryption vs. hashing
When talking about database encryption, you might be thinking about symmetrical encryption. This kind of encryption works by using a secret to encrypt and decrypt a secret.
You could use this method to encrypt your token password, decrypt it when needed to compare against the provided value. Howeer, there's actually no need to do this and it would be quite dangerous. Indeed, if your encryption secret is leaked alongside your database, anyone could decrypt the whole database and read the passwords in clear text.
Using a cryptographic hash function instead makes sure that you can compare the provided password for authentication, without having to decrypt the stored password from the database. Do this.
The recent attack campaign against Heroku and GitHub is a great demonstration of why securing your tokens is primordial.
 Myles Borins
Myles Borins
One important thing: as the token password is hashed, there is no way to retrieve it later. This is a great protection against attack, but can be surprising in terms of user experience.
For example, PyPI, the Python package repository, got everything right: they prefix tokens with pypi- making it easy to recognize them, and warn you that you need to copy your token as it won't be available again once you leave the page.
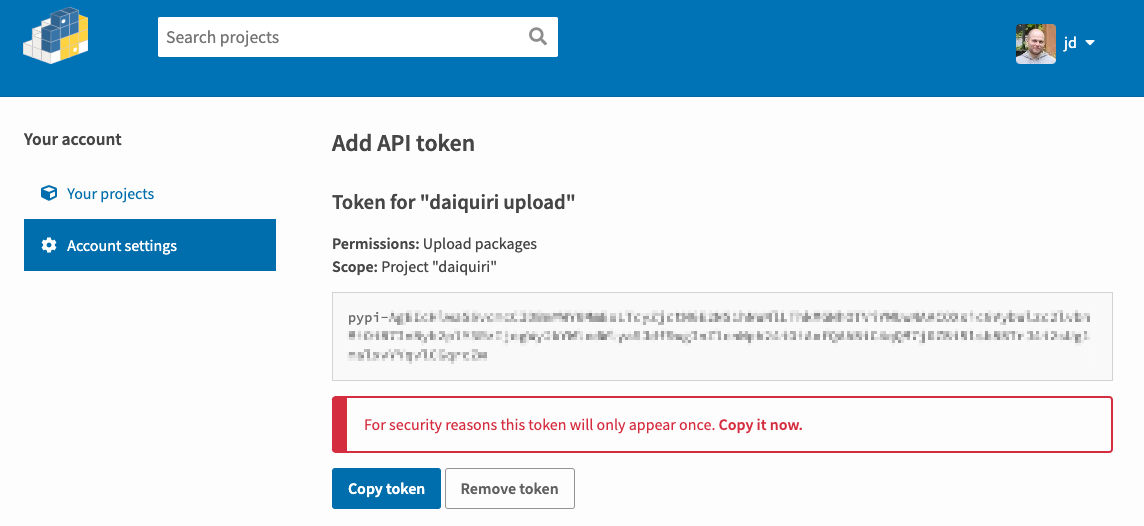
For better usability, you may allow your user to be able to identify their API key. To do that, you could provide them an API endpoint to get some metadata about the key (name, owner, permissions, creation date…).
Scope and Permissions
Not all the application that users build need to have the same access level. Using scope properties to your API key is an important of security.
Those level of accesses might be based on functional scope (some endpoint are allowed, some are not) and based on data access (e.g., read vs. read/write).
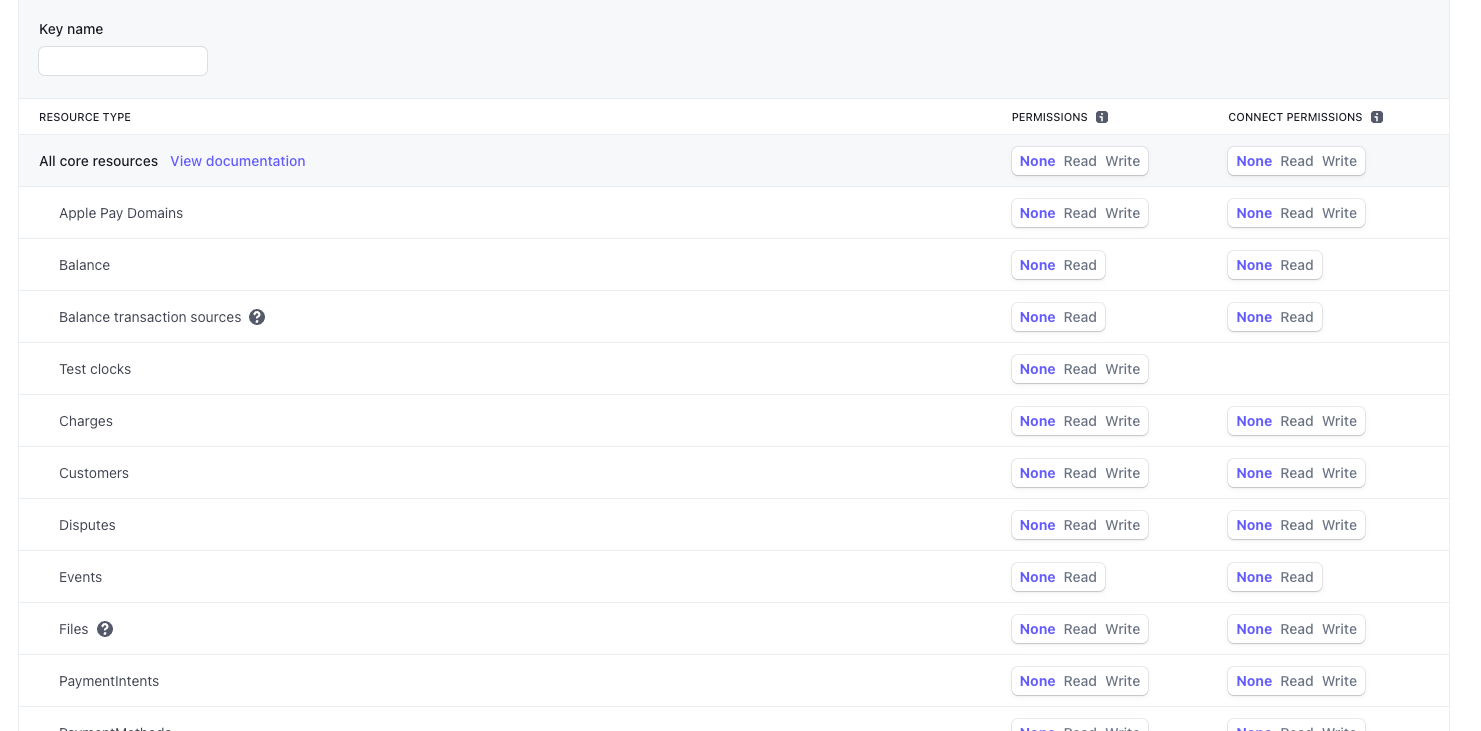
API Key Checklists
As a summary, we're providing two checklists below that can be used for two different things: one is for assessing a provider good practice with respect to its API keys, the other one being a checklist for assessing your own API key implementation.
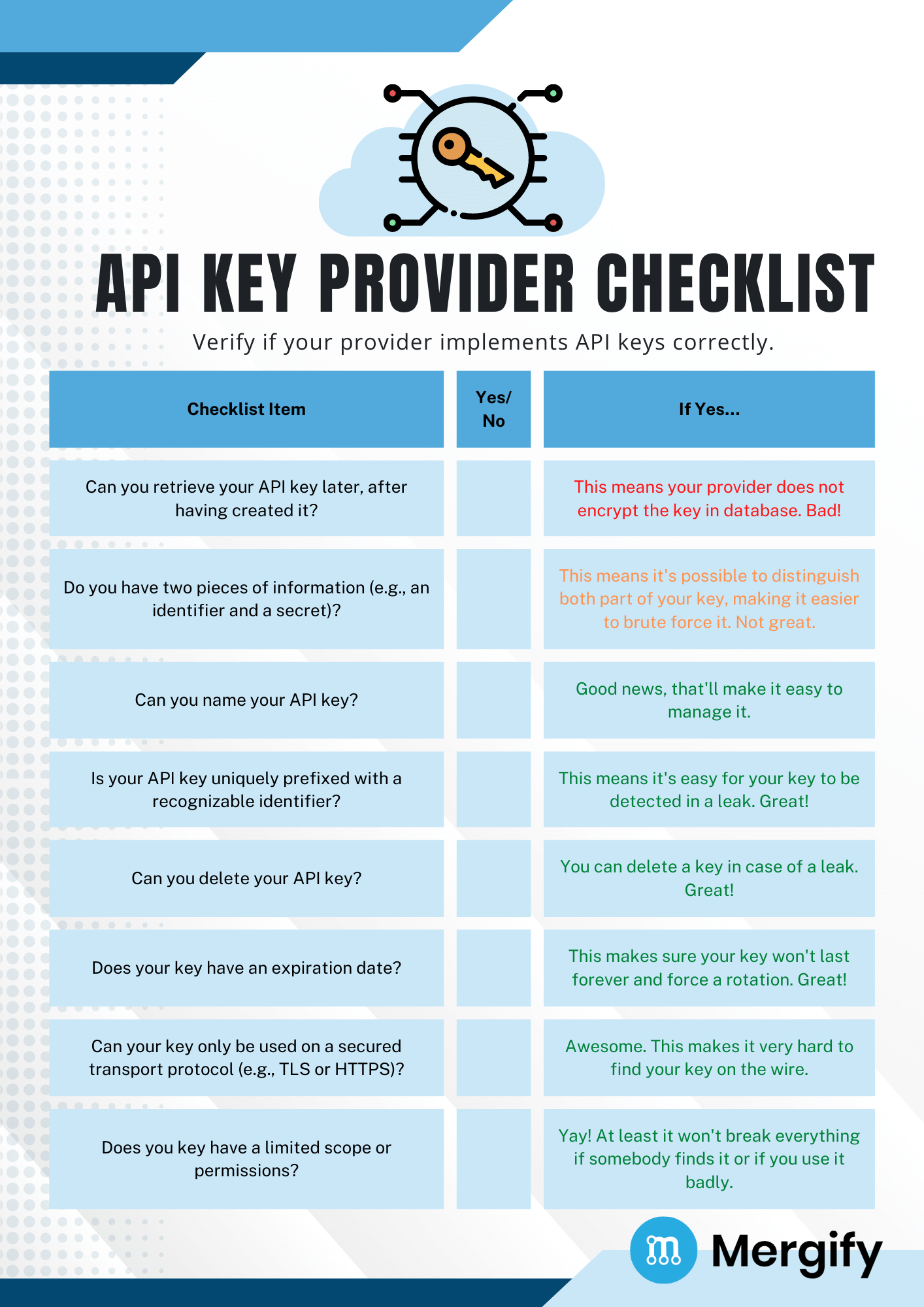
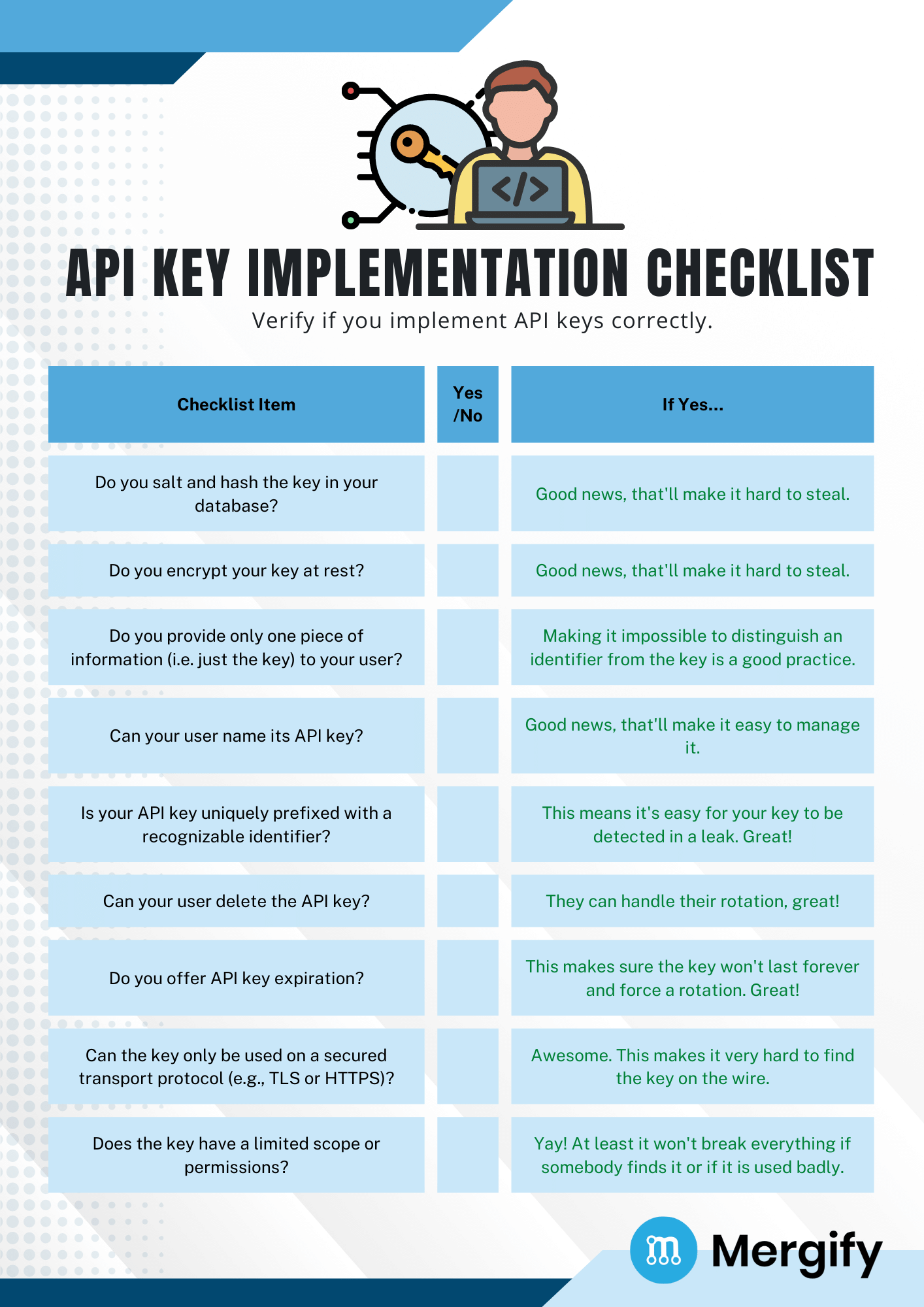
Feel free to use those cheat sheets as verification list when assessing one of your provider, or when building your own API key implementation.