Truncating your SQLAlchemy/Alembic Migrations History
This article talks about the versioning of databases in a Python app with SQLAlchemy and Alembic and shows why and how Alembic history should be truncated to better maintain the history.


If you maintain a Python application that relies on a relational database, you are probably familiar with Object-Relational Mappers like SQLAlchemy. If you don't, maybe you should consider using one! ORMs are portable and allow you to interact with your database tables in an object-oriented way. They take care of the boilerplate code to interact with the database, making your code safer and easily maintainable.
Now, what happens when your application evolves and you need to introduce changes to the database? Well, you could deploy your changes and perform the DDL associated with your modifications in the production databse. Or maybe implement your own SQL script systems. In this article, let's talk about how it is possible to implement a robust versioned system of DDL migrations with Alembic and what limitations it can cause when the version history becomes very long.
Why You Should Version Your Database
A database migration file will contain the DDL instructions to bring modifications to the database data structure. It has a unique identifier, and it is linked to the previous version and the next in a linear history.
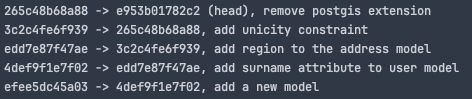
alembic historyA significant advantage of versioning your DDL changes is traceability. Indeed, all the versions should be committed to your VCS tree together with the code change, thus helping you trace back the evolutions made and the reasons why. They are a sort of documentation of the history of your app's database!
Then, a migration will help you reproduce the desired database state. For example, if your whole database becomes corrupted or lost, and your last backup dates back three days, you will need to restore it to this available state. With your migrations, you can identify the version matching that backup, and you can catch-up with the latest version by re-running subsequent migrations from there!
Before talking about Alembic migrations, let's talk a little about automation. Indeed, since migration files are versioned and incremental, they can efficiently be run in a dedicated database upgrade step of your Continuous Deployment pipeline. Right before the application's deployment step, that new step compares the current database version and the latest version newly added to the code. Then, the database is automatically updated by running all new subsequent migrations to the current version.
SQLAlchemy and Alembic Migrations
The ORM SQLAlchemy is a robust and complete library that interacts with your database in a Pythonic way. You can use it by simply declaring tables as Python classes inherited from a so-called "Declarative Base." The lib will then map your Python classes to the database object.
An operation like creating all your relations in an empty schema is made very simple because SQLAlchemy holds the metadata associated with all of them. Running this helper on the metadata performs whatever CREATE ... operation is necessary and, most importantly, automatically orders the SQL statements correctly!
Alembic now comes into play by offering a configurable API that uses the SQLAlchemy metadata. When an SQLAlchemy Python class is altered, for example, a new attribute is added, a simple call to the alembic revision CLI, with the autogenerate flag, can compare your existing history with the current state of the metadata. The change is then automatically written in a new "head" migration Python script added in the dedicated versions directory. Of course, you can edit or write your migration scripts manually using the API. Commit it to the VCS with your change, and you are good for the next deployment!
The Issues With Long Migration History
Now that you have added a test database to your pipeline to test your latest increment, or if you use the alembic history in a local database test setup, you may notice in the logs that the list of performed migration increments grows longer and longer with time! Since each change has been tracked and is performed one after the other, Alembic will run each DDL instruction from the creation of your first model up to the current state of your application.
This becomes costly and pointless, mainly because some models or attributes may have existed and have gone since you first started versioning! Everybody has read the book at some point, and no one is interested in the story's beginning anymore.

The solution is pretty straightforward: you need to truncate your history and write a new baseline migration at some point.
Truncating Alembic Migrations
Before rewriting the history, keep in mind that you must choose the new start database state wisely! At Mergify, we support older versions for on-premise deployments, so we decided to truncate following our latest supported version of the application.
Let us take a look at the bash script written for this purpose:
#!/bin/bash
truncate_hash="$1"
echo -e "\n-- Truncating alembic revisions up to $truncate_hash --\n"
if ! [[ $truncate_hash =~ [a-f0-9]{12} ]]; then
echo -e "ERROR: please provide a valid revision hash as input parameter\n"
exit 1
fi
migrations_dir="path/to/migration"
versions_dir="$migrations_dir/versions"
versions_tmp_dir="$migrations_dir/versions_tmp"
# Upgrading database up to the version to truncate
alembic upgrade "$truncate_hash"
# Deleting old migrations
delete_old_migrations() {
while read -r line; do
if [[ $line =~ [[:space:]]([a-f0-9]{12}) ]]; then
hash="${BASH_REMATCH[1]}"
deleted_file=$(find "$versions_dir" -maxdepth 1 -type f -name "*$hash*" -print -delete)
echo "- deleting old migration file: $deleted_file"
else
break
fi
done
}
# Run the command and redirect the output to a temporary file
alembic history -r ":$truncate_hash" | tac | delete_old_migrations
# Move the content of mergify_engine/models/db_migrations/versions to a new mergify_engine/models/db_migrations/versions
mkdir -p "$versions_tmp_dir" && mv "$versions_dir"/*.py "$versions_tmp_dir"
# Switch to use the reflected metadata in env.py
export MERGIFYENGINE_TRUNCATE_WITH_REFLECTED_META=1
# Create the truncated revision
alembic revision --autogenerate -m "Truncated initial revision" --rev-id "$truncate_hash"
# Move back the stuff from versions_tmp to version and delete the tmp folder
mv "$versions_tmp_dir"/*.py "$versions_dir" && rmdir "$versions_tmp_dir"
echo -e "\n-- Migration successfull. Beware of the potential following manual changes. --"
echo -e "-> Imports and manual additions/deletions in the resulting initial version."
echo -e "-> Run the migration to heads and test."
First, we place ourselves in a configured environment with an empty database. We input the hash of the migration, which will be the new starting point. Alembic runs the migrations up to this point included.
We temporarily move the newer migrations files and delete the old ones to have a cleared migrations folder.
Now, there is a subtility. Let us look at a snippet of the modified alembic env.py used for the script.
def do_run_migrations(
connection: sqlalchemy.Connection,
) -> None:
if (
from_reflected_metadata := os.getenv(
"TRUNCATE_WITH_REFLECTED_META",
)
) is not None:
metadata = sqlalchemy.MetaData()
metadata.reflect(bind=connection)
# NOTE: drop tables after getting metadata with reflection
# to allow alembic to autogenerate the migration file comparing
# the metadata and the current state of the database
metadata.drop_all(connection)
else:
metadata = models.Base.metadata
context.configure(
connection=connection,
target_metadata=metadata,
transactional_ddl=True,
transaction_per_migration=True,
compare_type=True,
)
with context.begin_transaction():
context.run_migrations()Remember the SQLAlchemy metadata we talked about in the first part? It is used to autogenerate the migrations. This means that before dropping the tables to rewrite the new baseline, we need to cache it filled up with the current state!
Back to the script, that flag is set, and the new baseline is finally autogenerated (note that it forces the current hash to this newly generated version to ensure compatibility with the following migrations). Finally, move the next migrations back to the folder to keep them untouched.
Conclusion
Setting up SQLAlchemy with Alembic will be a great must-have when your application grows and the collaboration on your repository increases. Although it requires some setup, it will increase your level of automation, history introspectability, and the reliability of your deployment process. I can only encourage you to read Charly's article for the testing part of the migrations.
At some point, your history grows too big and is no longer useful, as it can slow down the deployment process. This article provides a solution to easily truncate the history to a fresh baseline.