They use Mergify: PyTorch Lightning


At Mergify, we want to show you that companies have different use of our software. Any workflow isn't the same! So for the very first time, we decided to launch a post series called #TheyUseMergify. Enjoy this first one 😁
They use Mergify: PyTorch Lightning
Every day, major projects use Mergify to automate their GitHub workflow. Whether they have a core team of 3 or 50 people, the one thing they all have in common is the project leads are willing to let their developers focus on what’s really important—code. So we decided to meet with some of them to get to know more about their challenges and discover how Mergify helps their core team be more efficient when it comes to pull requests. For our first interview, we caught up with Jirka Borovec, a lead contributor of PyTorch Lightning, an open-source project based on PyTorch that already has more than 16,000 stars and 500 contributors on GitHub.

Could you give us a short outline of the PyTorch Lightning project?
Sure! PyTorch Lightning is actually a way of organizing research code without the boilerplate on PyTorch, one of the most popular frameworks in the fields of machine learning and deep learning currently. PyTorch is a very efficient framework, but it is also very complex and without any strict structure for users. So we created PyTorch Lightning to build on the best practices for research and implementation and to make deep learning accessible to anyone, even beginners. In a way, PyTorch Lightning is to PyTorch what the code formatter Black is to Python—a tool that helps implement standards so that engineers can share their code more easily and work better together. We also provide a set of training abstractions and maintain training processes, so the user doesn’t need to worry about all the boilerplates with the training and can really focus on how to interpret the data and what model to use.
Are your users mainly PhDs?
Not really. Today, our users are very diverse—we have master’s students and universities, but also big companies like Nvidia, Facebook, now Meta, and Uber. On GitHub, you can see the list of the 5,800 projects that have PyTorch Lightning as a dependency and whose domains are eclectic—they range from medical imaging to recommendation systems.
How big is the core team?
The core team is composed of 8 people working on the main project, pytorch-lightning, but also on other projects like lightning-flash, lightning-bolts, lightning-transformers, ecosystem-ci, and lightning-tutorials.
Could you briefly describe the GitHub workflow on those repositories?
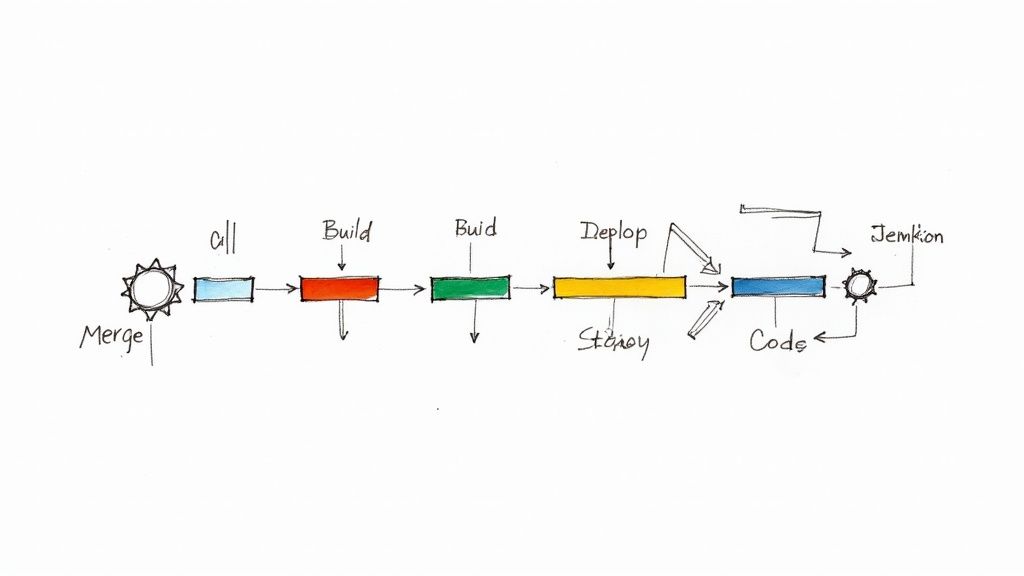
On our main repositories, each pull request [PR] needs to get three approvals to be merged with the branch “master”—one approval from the code owner of the particular codebase section and two approvals from anyone else in the core team. In terms of continuous integration [CI], we include both mandatory and optional tests, with mandatory tests representing about 70% of the total number of tests. We run about 40 configurations to test each PR with the multiple operating systems, Python and PyTorch versions, and scopes of tests, including full scope tests for CPU and GPU. And as we are using PyTorch, which itself has between 1 and 2 gigabytes of package, we build our own Docker images that are updated every time a PR is merged with the branch “master.”
What are the main challenges with this workflow?
Definitely the update of the PRs! We receive between 5 and 10 PRs a day, so we often have several PRs ready and waiting to be merged.

And updating those PRs each time one is merged can quickly cause a bottleneck, because you need to update them one by one.
Is this why you first crossed over to Mergify?
Yes, exactly! The automatic update was one of the first Mergify features we used, along with the automatic merge feature, which GitHub didn’t have back then.
Which other Mergify features do you currently use?
The labels and the ability to add reviewers, mostly. Labels are very useful to indicate the stage of each PR. When there are about 100 opened PRs in the backlog, we don’t have time to check each one regularly, so it’s nice to be able to know at a glance if there is a conflict that needs to be resolved or if it is ready to go. Based on the conditions we’ve defined, those labels are added and removed automatically. The ability to filter by label is very convenient as well. The reviewers feature helps us to automatically add a third level of approval to fit our workflow of validation, as GitHub only allows us to assign a PR to two code reviewers.
What is your favorite Mergify feature?
It’s impossible to choose just one! With each of them, Mergify helps us throughout a PR’s life cycle, and that’s very valuable. You want to be able to automatically update the PRs when they are ready to be merged, but you also want to know when PRs are ready to go so you can pay special attention to them. And a label to indicate if a PR has any conflicts is a good way to let the author know why his work has not been merged yet.
What has been the biggest impact of using Mergify on your team’s performance so far?
Using Mergify has definitely been a very positive move for the core team. Developers don’t need to handle boring duties anymore, like updating PRs or manually applying the “ready to go” label. This means they can focus on more interesting tasks.
What would be your N°1 tip for someone who’s new to Mergify?
I personally like to use the Mergify UI to check the rules I write for target PRs. In there I usually test PRs that should not be touched to be sure that they will work correctly.
If you had time to contribute to the Mergify project, what would you choose to work on?
I’ve actually already opened 4 issues and made one PR for the Mergify documentation that described some of our corner cases. But if I had to contribute again, I would like to add the ability to manage labels for issues as well. Mergify doesn’t cover this currently and it would be a great new feature!