Post-mortem for May, 16th 2025 incident


On May 16th, 2025, Mergify experienced a significant service disruption from 06:00 UTC to 09:51 UTC. This post-mortem outlines the incident's context, our response, resolution, and the steps we're taking to prevent future occurrences.
Context
Mergify's infrastructure is hosted on Google Cloud Platform (GCP), utilizing Cloud Run with Direct VPC Access to connect our services securely to internal resources. This setup is designed to ensure optimal application performance and security.
At 06:00 UTC on May 16th, our monitoring systems alerted us to a major outage affecting all our services, including the dashboard and engine. Initial investigations indicated that all Cloud Run containers had been scaled down to zero, and new instances failed to start due to failed health checks.

Investigation
Upon receiving the alerts, our team promptly initiated an incident response. Early diagnostics revealed that the issue was not application-related but stemmed from the underlying infrastructure. Specifically, Cloud Run services were unable to start new instances because health checks failed, and no application logs were emitted, indicating a failure occurring before the application startup.
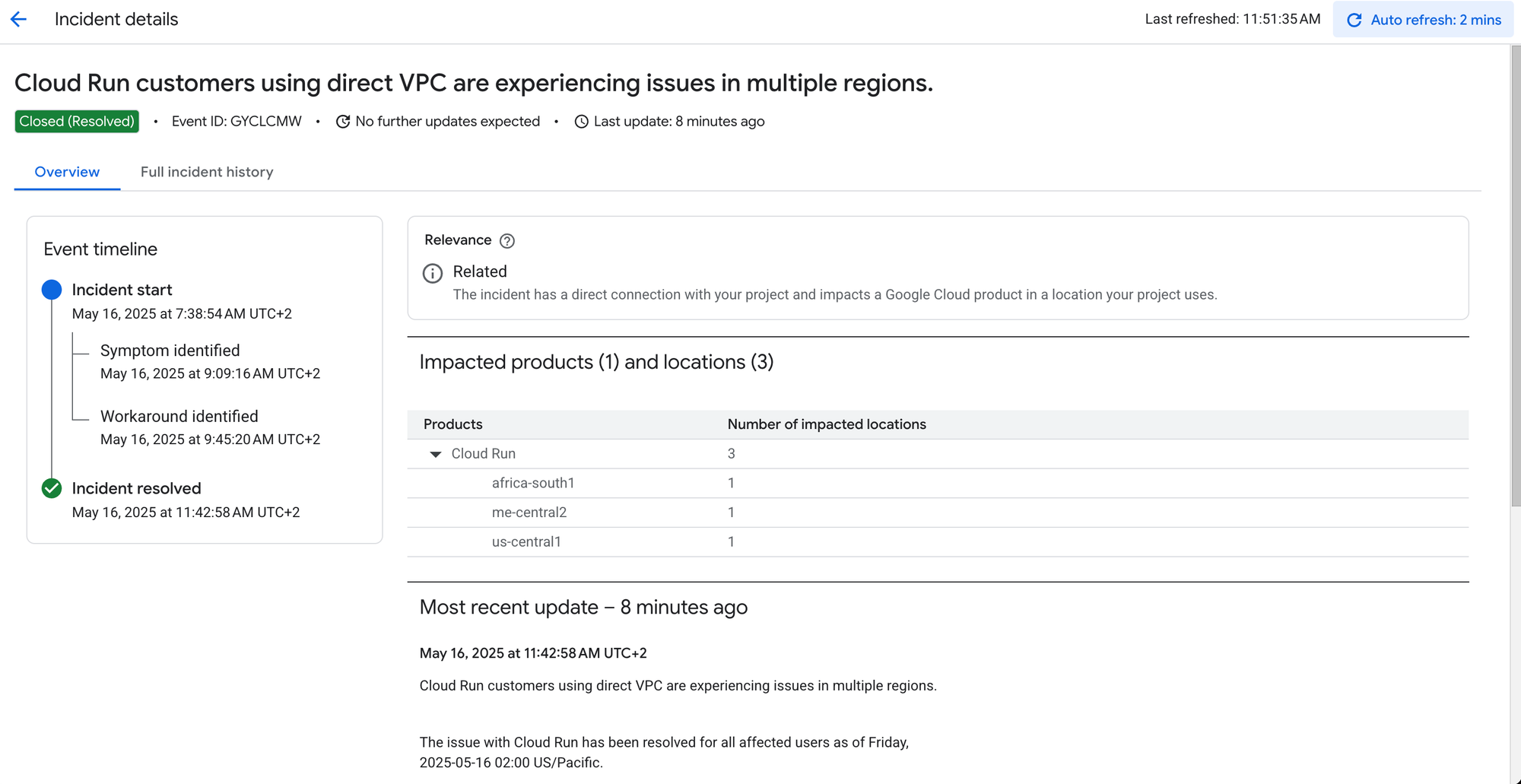
We attempted several recovery actions, including redeploying resources and recreating the subnet, but these efforts were unsuccessful. By 08:15 UTC, we escalated the issue to Google Cloud Support. At 08:47 UTC, GCP acknowledged an ongoing incident affecting the Cloud Run Direct VPC Egress feature and provided workarounds. However, before we could implement these solutions, GCP resolved the underlying network issue at 09:51 UTC.
Resolution
Once GCP resolved the network issue, our services began to recover. We closely monitored the system to ensure stability and confirmed that all services were operational. The incident was officially closed at 11:05 UTC.
Learnings and Future Improvements
This incident highlighted a critical dependency on a single GCP region and the need for improved disaster recovery strategies. To enhance our resilience, we plan to implement multi-region deployment capabilities to allow rapid failover in case of regional outages.
These measures aim to reduce recovery time and maintain service availability during unforeseen infrastructure failures.
We apologize for the inconvenience caused by this outage and appreciate your understanding as we work to strengthen our systems against future incidents.