Level Up Your Docker Security: Uncover Mergify's Battle-Tested Workflow for Container Image Scanning


At Mergify, we use Docker containers to run our production environments. Containers help developers deliver their code faster and ship their features in a snap, and they are now used substantially in most software-centric organizations.
We are no exception. We build our images, run them, and ship them to customers as part of our on-premise offering.
A container image is a stack of layers composed of software. Mostly open-source software.

This is where the trouble starts.
Containers represent a major security risk. Vulnerabilities are hidden everywhere: in the code, in software dependencies, in the container itself, in the host operating system, etc. Every layer composing your image can be a threat.
Any base Docker image you use today contains tens of (documented) vulnerabilities.
Consequently, anyone of your container images can contain hundreds of vulnerabilities. Each vulnerability can potentially be exploited, breaking your production environment and leaking data. Of course, feel free to imagine the worse here.
This is not new: managing vulnerabilities has already been an issue with non-container systems and deployment. What changes is the order of magnitude of complexity that the production team has to handle. With a computer able to run thousands of containers, a single computer might have millions of security issues.
There might be millions of security issues on a single computer.

To mitigate that threat, you need to scan your container images regularly to find and report vulnerabilities of the embedded dependencies.
There are a lot of good tools out there that can inspect an image for Common Vulnerabilities and Exposures (CVE) — we have tested a few of them and struggled to find a great solution.
Testing multiple solutions, we soon realized that the real problem was not scanning images. There are a lot of good scanners on the market. Each one uses mostly the same public databases of vulnerabilities.
The real problem is the vulnerability lifecycle.
Most unveiled vulnerabilities are just ignored because they don't represent any threat to your application. Let's say you use the Ubuntu official image. This image includes open-source software, like cURL. Vulnerabilities are found regularly in such software, but the vulnerability can be ignored if your code doesn't use it. However, if you choose to ignore the threat, you must track why you ignored it — while being notified about any severity change.
That's where the real value should be in such tooling. Vulnerability lifecycle management.
Like many companies, we took a build vs. buy approach to solve that problem, and we started our journey by looking for software available from the shelf.
Commercial Software
The first thing we tried is commercial software. There are a few available, such as Snyk. They offer many tools to find vulnerabilities in code, dependencies, containers, and infrastructure as code (IaC). Security experts qualify each vulnerability to help you prioritize the fix.
Most of those tools can scan your container images for vulnerabilities, including the container's open-source dependencies. Every newly discovered vulnerability is sent to you via email, Slack, or other integrations. These vulnerabilities are prioritized based on their context and exploitability. This way, you can prioritize vulnerability fixes or ignore them if it doesn't represent a threat to your production.
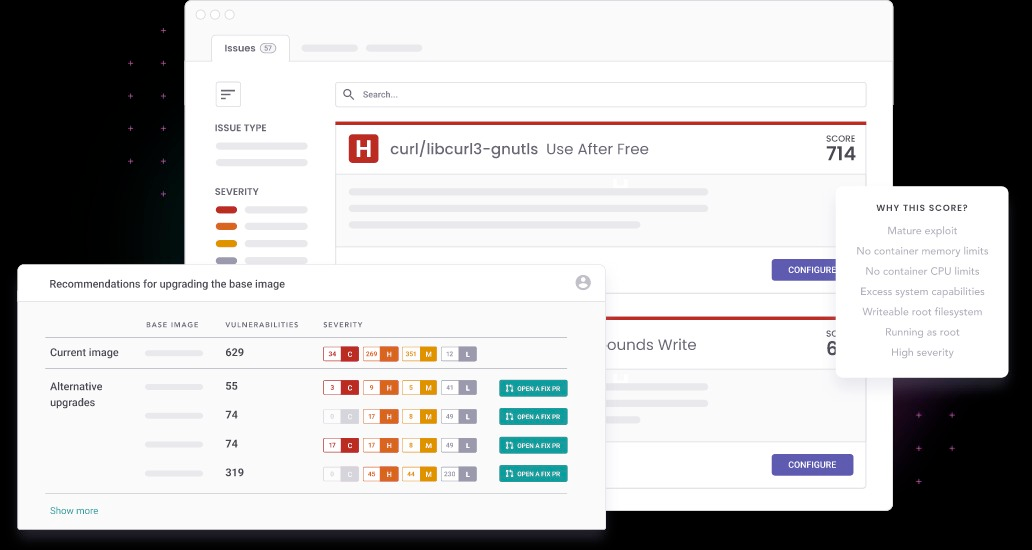
The problem is that every commercial software we tested did not solve the lifecycle management problem. Some of those seemed to be good solutions initially, and we used some to scan our Docker images. We were notified of every new CVE. Each one was either fixed or ignored after an examination.
The problem is that they always had a gap in management. For example, with Snyk, we lost the history of all the ignored vulnerabilities on every base image update — which happened quite often. Every time Python releases a new version, we have to update the base of our Docker images, which made the whole vulnerability history disappear. We had to start over with triaging vulnerabilities on each new release, making that tool unusable. 😭
Building Internal Tooling
After talking to many security vendors and spending hours testing software, we decided to develop our process and tooling. The goal was to make this cheap and easy to manage, as we have no bandwidth or resources to build and maintain a gigantic piece of software. Therefore we moved on to open-source security scanners in our research to be able to implement most of the missing parts ourselves.
We stumbled upon Trivy, which is yet another vulnerability scanner called. It isn't any better than other scanners. As I said, some public databases reference common vulnerabilities, so the value is not there. There are a lot of good scanners.
However, Trivy has helped us solve our vulnerability lifecycle problem.
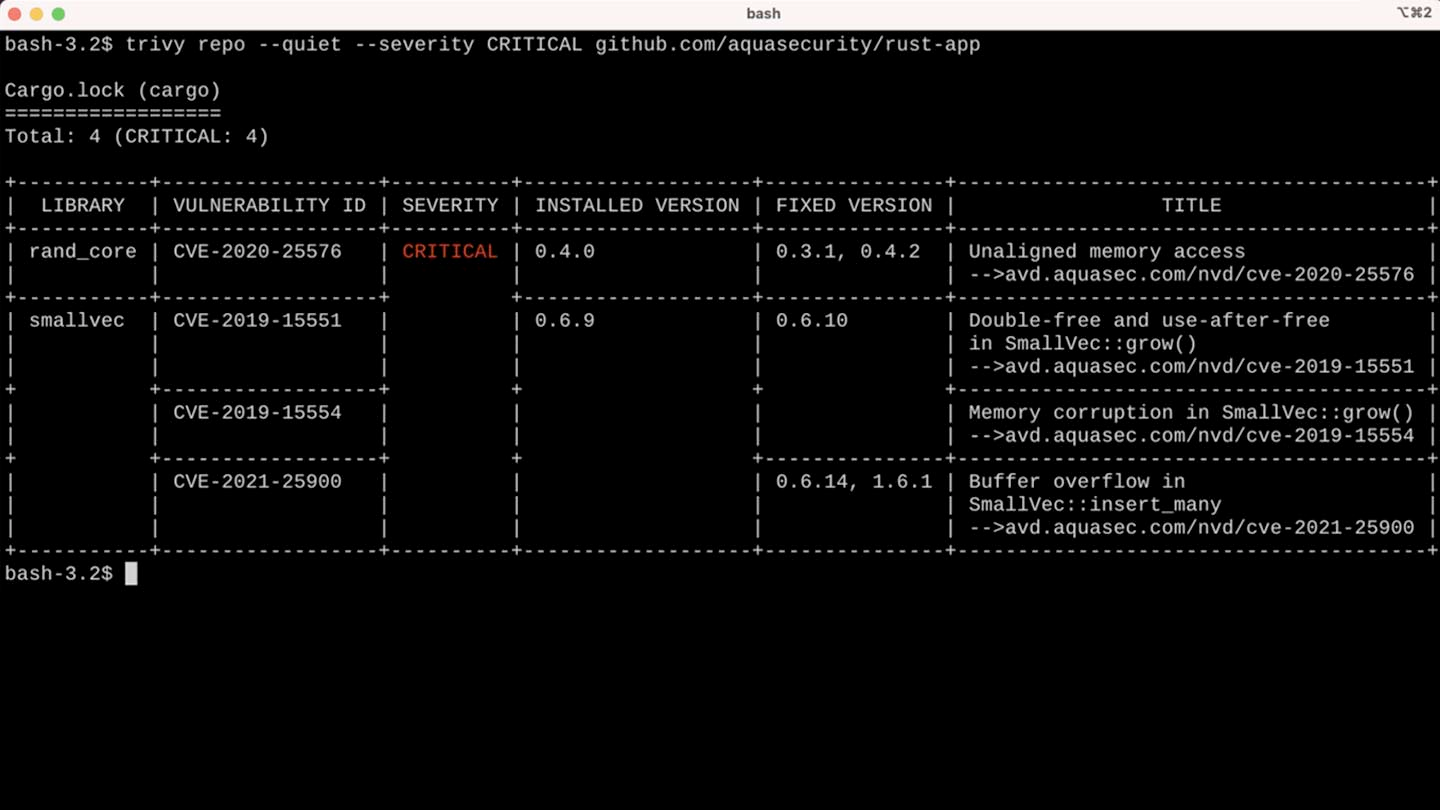
First, Trivy is an open-source and free-to-use scanner. It is easy to use in a lot of contexts. One of the great things about Trivy is that it can generate a JSON file that includes all the CVEs that affect your image.
This is how we had the idea to build our original workflow. 💡
The Workflow
We soon realized that managing a history of vulnerabilities would be easier using a DVCS like Git rather than building complicated tooling. We decided to leverage Trivy JSON output and commit the result in our Git repositories. That ensured we properly tracked the different scans we were doing over time. By leveraging a Git-based workflow, everything became easy for us engineers.
The workflow we imagined was simple:
- Run an image scan every day.
- Create a pull request with the changes detected.
- If there are no new CVEs, we can merge the changes automatically. Usually, this happens when new details are added to existing vulnerabilities. There is no need for a human to review this.
- If new CVEs are detected, label the pull request as such and wait for humans to either: a. fix the image by removing the vulnerability or b. approve the pull request and acknowledge the introduction of those new CVEs.

By running this workflow every day, we made sure we checked all the requirements we had when designing our close-to-perfect vulnerability lifecycle management:
- Is auditable: ✅
- Is automated: ✅
- Is versioned: ✅
- Needs humans only to acknowledge or remediate new issues: ✅
- Is self-documented: ✅
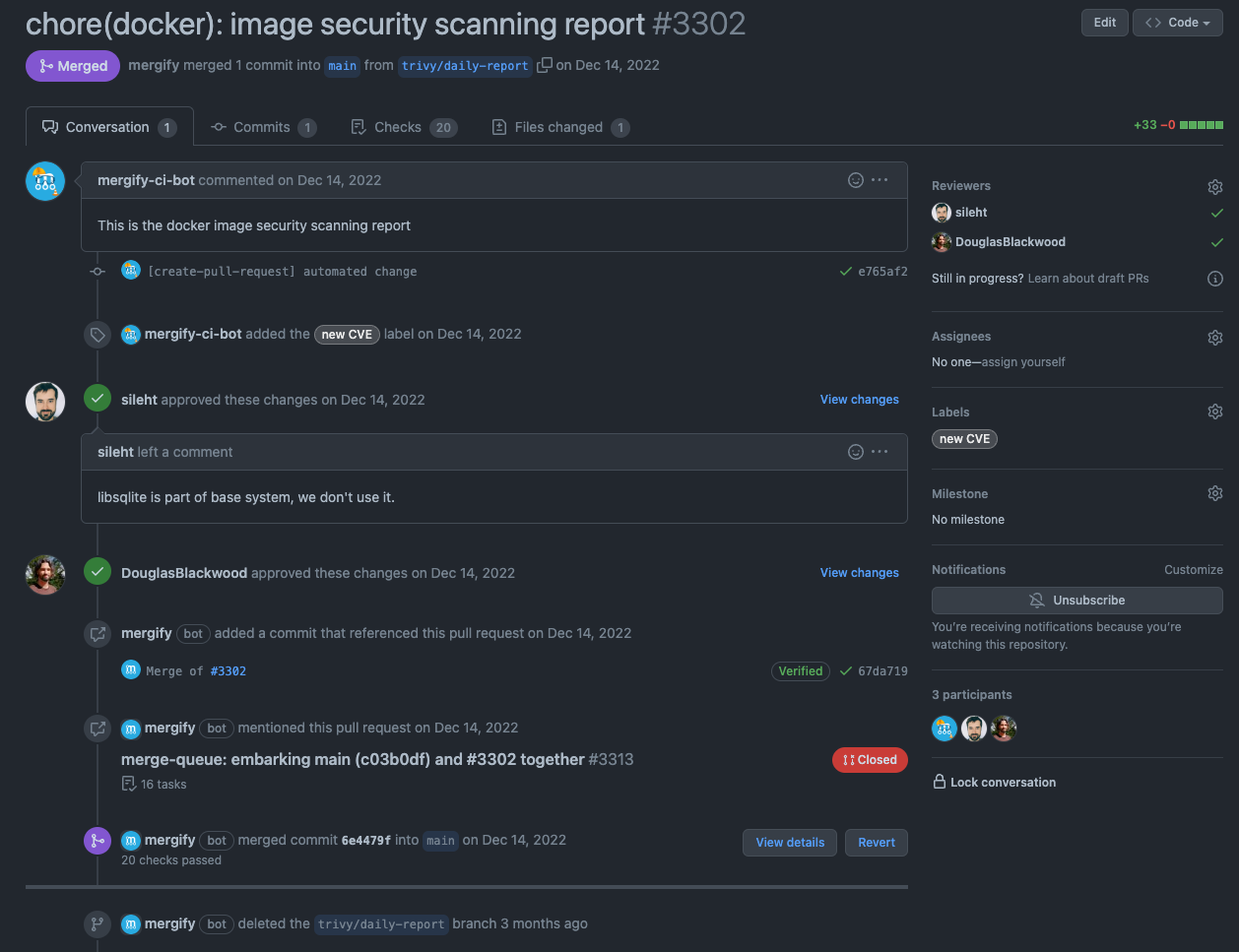
In Practice
We use GitHub Actions to create the daily vulnerability report. We commit this report in the repository, so the GitHub Action has to create a pull request on every report change. Here is the code we're using today:
name: Scan docker image
permissions: read-all
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
concurrency:
group: "${{ github.workflow }}-${{ github.ref }}"
cancel-in-progress: true
jobs:
docker-image-security-scan:
timeout-minutes: 10
runs-on: ubuntu-20.04
steps:
- name: ⬇️ Checkout
uses: actions/checkout@v3.3.0
- name: ☁️ Download latest image
run: docker pull registry.heroku.com/mergify-engine/web:latest
- name: Run Trivy vulnerability scanner
uses: aquasecurity/trivy-action@master
with:
image-ref: "registry.heroku.com/mergify-engine/web:latest"
format: "json"
security-checks: "vuln"
output: "docker-security-scan.json.tmp"
- name: Keep only the results section
id: update
run: |
BEFORE="$(jq '.[].Vulnerabilities|length' < docker-security-scan.json)"
jq --raw-output '.Results | del(.[].Vulnerabilities[].Layer) | del(.[].Vulnerabilities[].LastModifiedDate)' docker-security-scan.json.tmp > docker-security-scan.json
rm -f docker-security-scan.json.tmp
AFTER="$(jq '.[].Vulnerabilities|length' < docker-security-scan.json)"
if [[ $BEFORE -lt $AFTER ]]; then
echo "labels=new CVE" >> "$GITHUB_OUTPUT"
fi
- name: Create the Pull Request
id: cpr
uses: peter-evans/create-pull-request@v4
with:
author: mergify-ci-bot <mergify-ci-bot@users.noreply.github.com>
title: "chore(docker): image security scanning report"
labels: ${{ steps.update.outputs.labels }}
body: >
This is the docker image security scanning report
branch: trivy/daily-report
base: main
This action does the following:
- Checkout the code;
- Download the Docker image;
- Run Trivy on the image;
- Check for new CVEs between the previous and the new vulnerability report;
- Create a pull request with the change, adding the
new CVElabel if new vulnerabilities are detected.
There is some magic there and there. For example, the JSON report is filtered with jq to drop all non-essential data and avoid noisy pull requests.
The final step is leveraging Mergify to merge every report without any new CVE automatically.
pull_request_rules:
- name: automatic merge from trivy
conditions:
- head=trivy/daily-report
- author=mergify-ci-bot
- label!=new CVE
actions:
merge:
method: mergeThat's it! While the team must review every new vulnerability, boring tasks are automated. This gives more time for engineers to investigate each new CVE, leave a comment, approve it if it isn't considered a valid threat, or find a fix. The vulnerability lifecycle is handled correctly and is not affected by events such as a base image update.
Go Further ❤️
For more, you can check out Trivy. It's a really good tool that can bring a lot of security to your project. As Mergify, which can automate some of your workflows. You could eventually develop a new one like this one and share it with us!

Mergify and Trivy are complementary to each other because they address different aspects of security in software development. While Mergify helps prevent bugs and vulnerabilities from being introduced into the codebase, Trivy helps identify and fix vulnerabilities in the dependencies of container images.
By using both Mergify and Trivy, you can ensure that your software development process is secure from the start and throughout the development lifecycle.