CI Failures Don’t Just Break Builds — They Break Focus


A few weeks ago, something broke in production.
No big deal — we've all been there. I did what I’ve done hundreds of times before:
Checked logs, wrote a patch, pushed to a new branch, and waited for CI.
Except CI failed. Not because of my change, but because someone had merged a PR 20 minutes earlier that broke main.

Now I'm stuck. The fix is ready, but I can't ship it without bypassing the tests or waiting for someone else to fix what they broke. From a clean engineering process point of view, this is a disaster.
So I face the same choice many of us do in this situation:
Force-merge the fix and cross my fingers, or hold off on fixing prod.
I clicked merge. Crossed my fingers. And hoped that while I fixed one problem, I didn’t just create two more.
CI doesn’t just fail. It fails at the worst possible moment.
You can build a beautiful, automated pipeline. You can configure your cache keys, lint your YAML, and badge your build.
But none of that helps you when:
- A flaky test randomly fails a PR at 6:30 pm
- GitHub Actions hits a Docker pull rate limit again
- A CI step you don’t control starts failing globally
And here’s the kicker: most of us rerun the job, get a green check, and move on. No root cause. No visibility. No long-term fix.
We’re debugging by ritual.
The real cost isn’t money — it’s momentum.
When CI breaks, you don’t lose dollars.
You lose flow.
You're in the middle of a fix. Or a feature. Or just trying to finish the last ticket of the sprint. CI breaks, and now you're digging through logs from a job you didn’t write for a failure you didn’t cause.
You rerun the job. Still red.
Rerun again. It’s green.
You merge, slightly less confident than before.
Your 20-minute bugfix becomes a 90-minute support fire. And you’re left wondering:
Did I actually fix the bug? Or did I just push the pain to Future Me?

Why do we tolerate this?
Because CI is treated like plumbing.
If it works, you don’t think about it. If it doesn’t, you patch it, rerun it, and carry on.
Nobody “owns” CI quality.
Nobody tracks flake rates in a dashboard.
Nobody budgets time for fixing transient failures.
And so it creeps.
What was a one-off rerun last week becomes standard practice. What was a reliable build becomes a minefield of red crosses and Slack pings.
So we started building CI Insights.
We didn’t want to replace CI. But we wanted answers:
- What jobs are failing the most?
- Are they flaky? Or actually broken?
- Which tests slow us down the most?
- What’s our actual lead time from PR to prod?
- Why are reruns our default fix?
So we built something that watches your CI without changing it.
No YAML edits. No instrumentation. Real-time observability and answers.
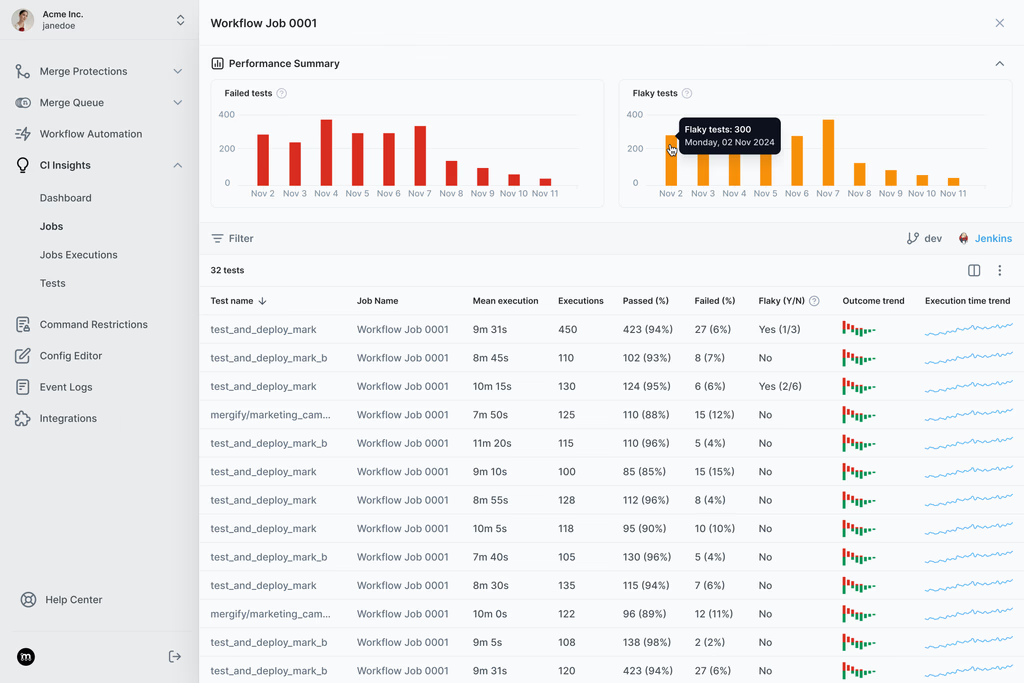
CI Insights tells us:
- Which jobs flake
- Which jobs got slower this month
- How much time does our team spend rerunning things
- How much merge delay CI is actually causing
- What our deployment frequency looks like (DORA-style)
It’s like going from looking at raw logs… to having a dashboard that tells you why your team is grumpy.
What you can do today
Even without CI Insights, you can start spotting CI drift:
- Track retry rates. If your reruns are increasing, something’s decaying.
- Monitor merge delay. If jobs block PRs more than they fail, you have friction.
- Surface flakes. Build a script that scans past failed-then-passed jobs.
- Watch the slow creep. Job duration going up over time? That’s silent tech debt.
CI isn’t a tool. It’s a mirror.
And when it breaks, it reflects the messiest part of our engineering process: the stuff we patch instead of fix.
Want to see your own CI like this?
We’re opening up the CI Insights beta for GitHub Actions users. It’s free while in beta and built for engineers like us who just want their pipelines to work — or at least make sense when they don’t.
We’ll show you:
- The flakiest jobs in your org
- Job cost and rerun trends
- Real-time CI status across repos
- Slack alerts and auto-retries for the noisy stuff
Or email me — we’re always looking for devs to help shape what CI observability should look like.