4 Reflexions on the design of the Merge Queue Freeze


Merge queues are at the center of the value offered by Mergify. The freeze feature we announced a few days ago gives our merge queues a whole new range of possible use cases. You can now make your queues follow your product development life cycle.
Though before coming up with a final solution, we confronted ourselves with a complete conceptual and technical challenge. This blog post aims to go through several highlighted points encountered throughout this process.
Picking the right word 💡
As usual with product design, our journey started with a question. They say there are two hard things in computer science, and one of them is naming, so this is what we started with:
What is the best way to express the act of stopping a system output from being processed?
At first glance, we were intuitively tempted to call it "pause." But pausing implies an interruption of the whole system, which was not the expected behaviour in our case. Indeed, we wanted the merge queues to be able to continue processing pull requests, as usual, running tests and checks without any impact on their core functioning.
The only thing wanted was not to merge the final result (the output).
We took another perspective by examining the term "isolation." The terminology seemed adequate since isolation doesn’t imply any stoppage in a system processing — it only entails that it’s going to be set apart from the rest.
Algorithmically speaking, the feature wouldn't isolate the queue because of the sequential way Mergify processes the merge queues (we’ll go through this later in this post). It would remain in the same place, in the same order as before the user applied the freeze, meaning that the term “isolation” was not appropriate. Moreover, the word would have been confusing on the user side since isolating one part of a system doesn’t mean it stops its output from being processed, which is initially the goal of our feature.
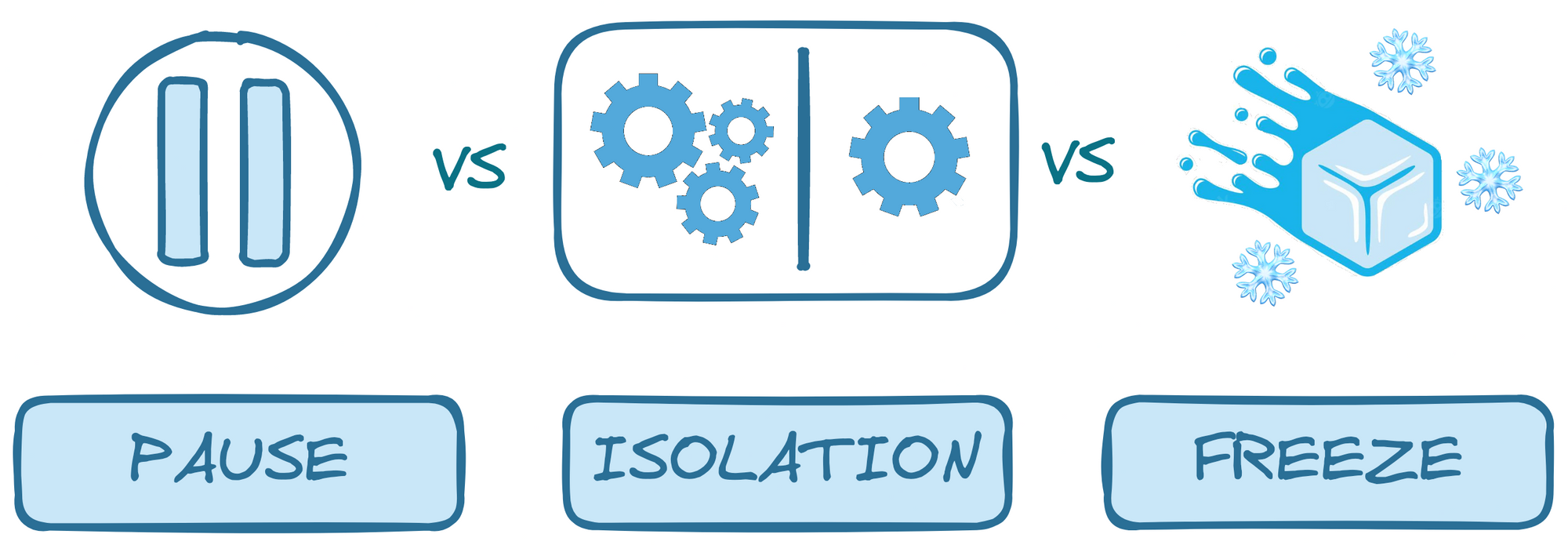
Moving on from those conclusions, we needed a way of expressing an action that lets the queue partially run while implying that it algorithmically stays at its place. This is where the word “freeze” came up and was deemed the acceptable way of expressing the fundamental behaviour of the feature. Freezing suggests that the subject stays in its place and is only stopped in time until it is thawed.
Applied to the final merge validation, it fitted how we wanted the feature behaviour to be understood.
Where to operate? 👨⚕️
After having conceptualised and properly grasped how the feature should behave, we moved on to the technical challenges encountered during the development.
But first, let’s dive more into the mechanic of how Mergify processes the merge queues.
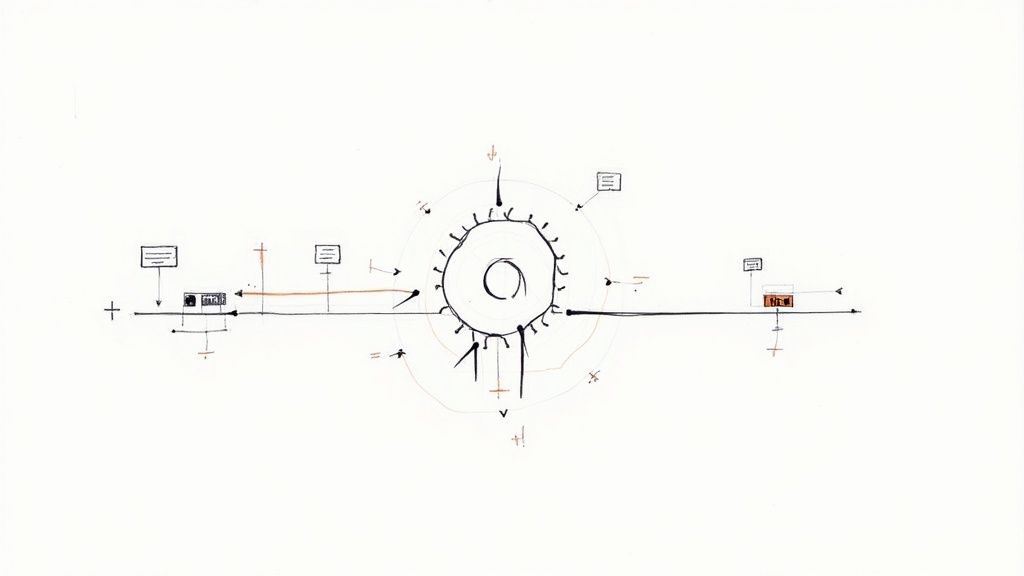
When several queues are defined in Mergify, the engine sequentially processes them, from first to last, in the order specified in the configuration. A queue is only treated when the previous queue finished processing all its pull requests is empty. Mergify tries to remove each pull request from the queue using a “merge validation function" that acts as a filter, determining whether the pull request can be merged or should be kicked out. This behaviour creates what we can assimilate to a waterfall system, in which if one level is blocked, the levels under will not be flooded by the water. Imagine that on every level of our waterfall system, there is a valve that can evacuate water when open and keep it contained when closed. However, the water contained in each level needs to be “treated” at any time. This is exactly how our new feature should behave.
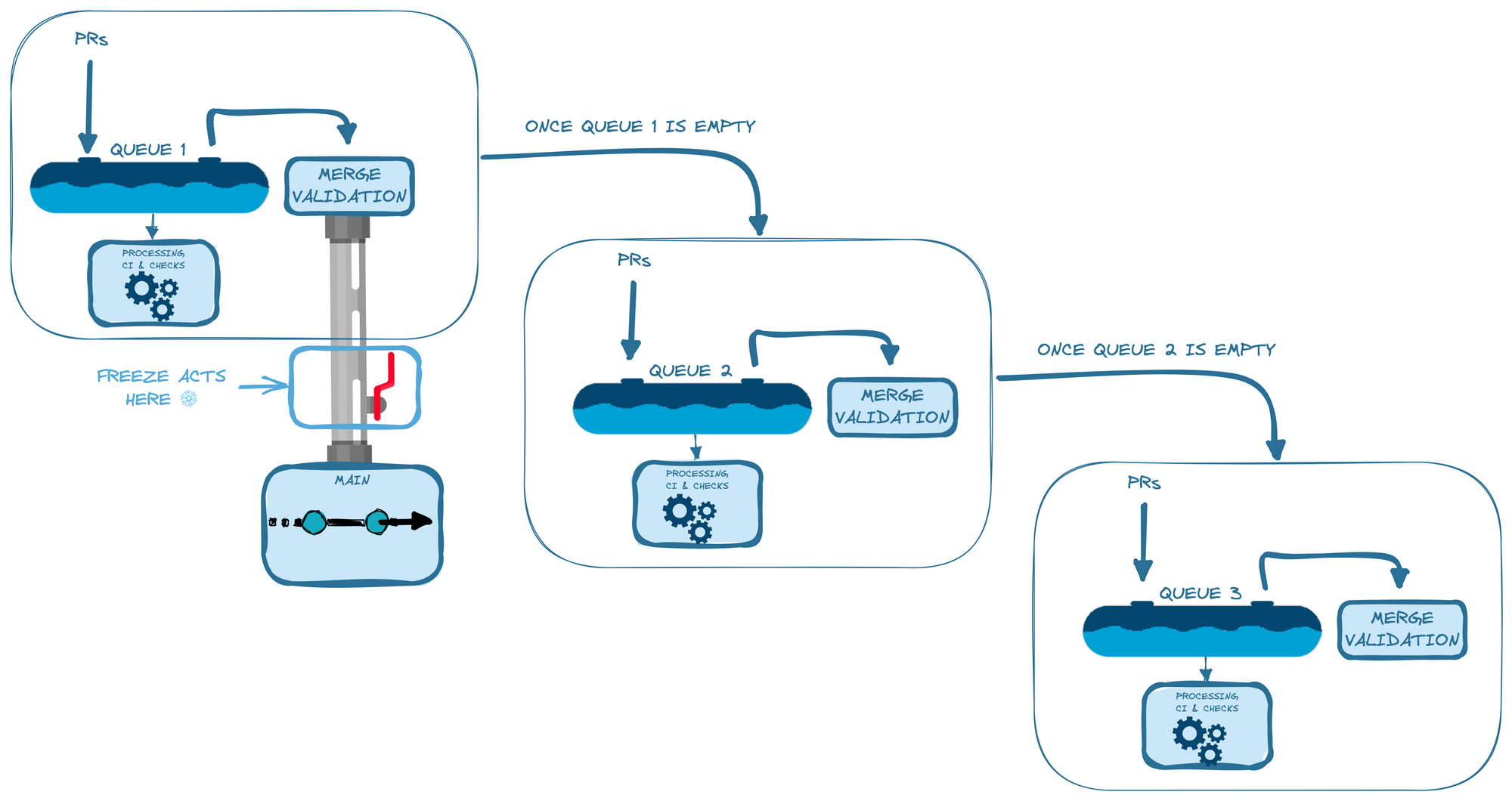
We knew that implementing the feature where the engine asserts if the pull requests are “mergeable” was the right choice. That way, we can ensure that even if a pull request is fully validated for merge, the code will be able to correctly block the queue and show the appropriate information to the user without interfering with the usual processing dynamic.
Designing the API 🖼
When designing APIs, it is crucial to think about simplicity and usability. Creating an API is like developing an application or a website: you need to put yourself in the user's shoes. You have to place simplicity at the heart of your design process.
In the case of an API, the user is a developer, like you. That makes the process a little bit simpler. You have to ask yourself the questions you would naturally ask yourself using any other API.
Following this philosophy, one of our challenges was to design a simple solution for the endpoints. Indeed, with the waterfall processing dynamic of the merge queues, when one queue is frozen, it mechanically means that all the queues below are also unable to merge.
It seemed then intuitive that if we froze a queue and stored data about it, Mergify should also generate data about the queues impacted below to have context information available at any time. The first implementation of our API endpoints had a 1:many relationship with all the queues and was generating data for each one impacted, according to the context.
We added endpoints with a 1:1 relationship to match every use case, with a more refined scope, for freezing and especially the unfreeze action. We were then handling several endpoints that had different scopes of actions, interacting with each other.
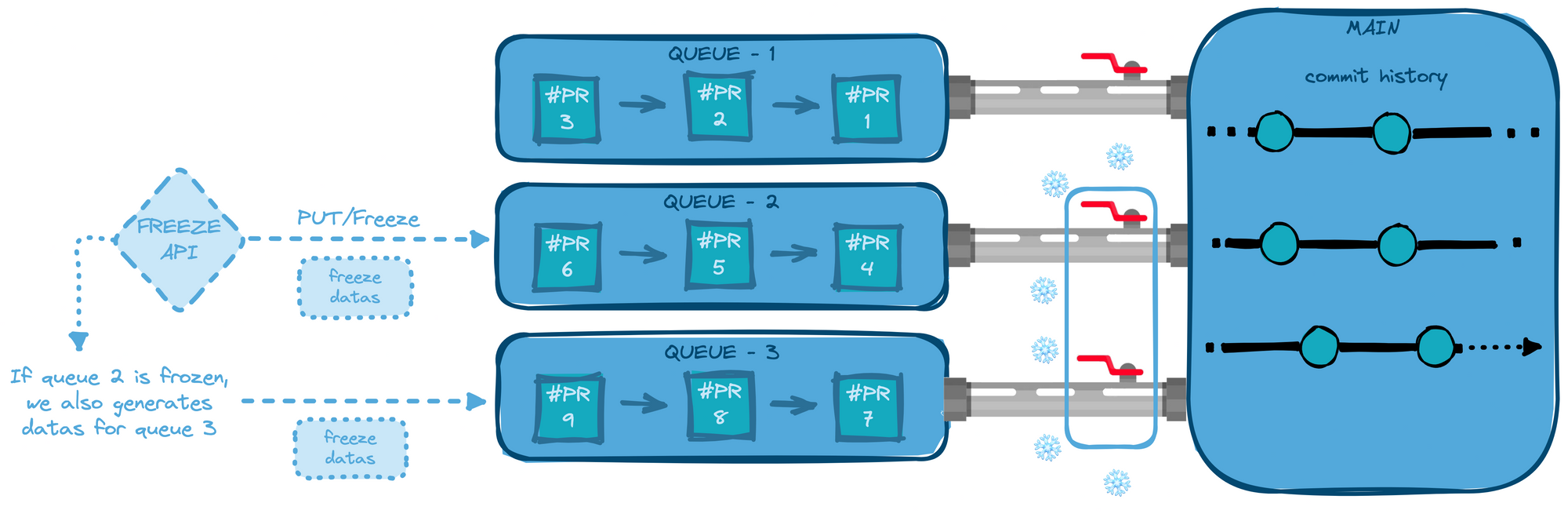
In reality, this was an overthought situation, and there were too many endpoints and written code for actions that were aimed to be simple and with fine granularity.
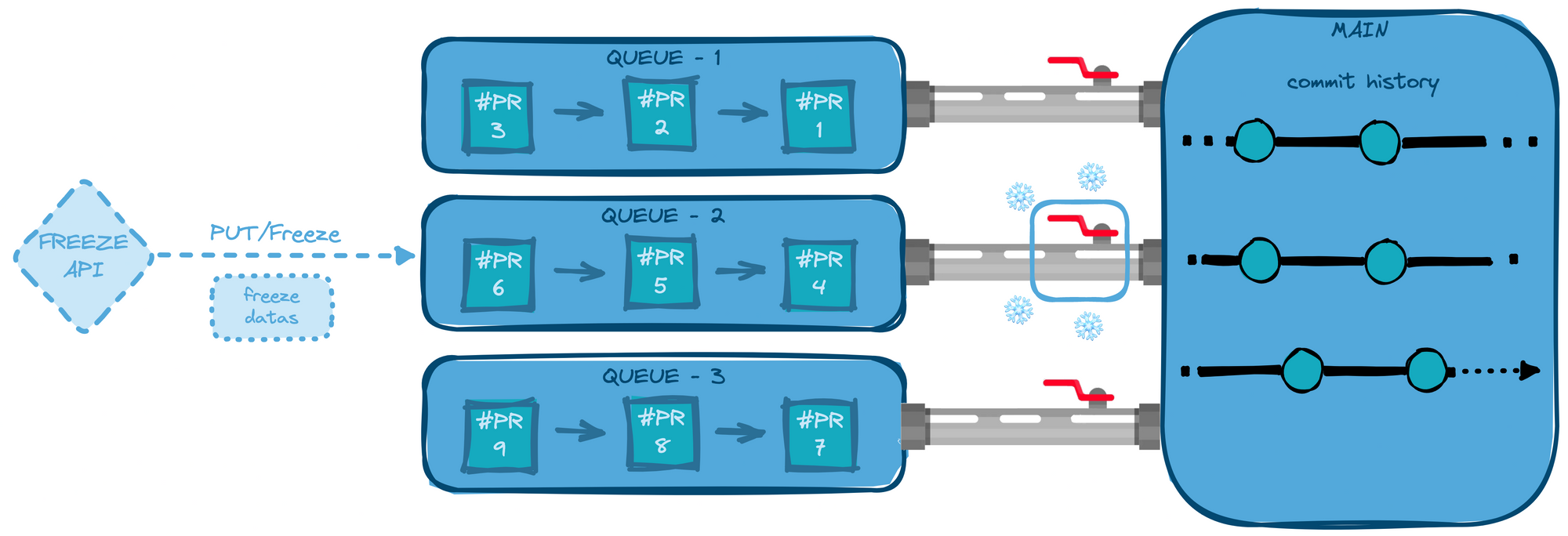
We remembered. When it comes to APIs: keep it simple. After tests and observations, we’ve concluded that it was necessary to generate data only for the targeted queue. The core mechanic of our merge queues was adequate for a more straightforward solution as our users know how our engine processes queues. Generating too much information would be confusing with the semantics. This also impacted data storage which led to useless data being stored where it was not necessary, increasing complexity.
Generating and processing data through 1:1 granularity endpoints gave our feature a much simpler experience overall while simplifying our code and API structure. In the end, conjugating the advantages Mergify's mechanics and keeping reduced scope for API endpoints leads to a minimised complexity and a better user experience. You can see the final list of endpoints in our API documentation.
What about the storage? 🎒
It's well known that we are satisfied users of Redis since it is robust, fast, and scalable. That's also what we decided to use here.
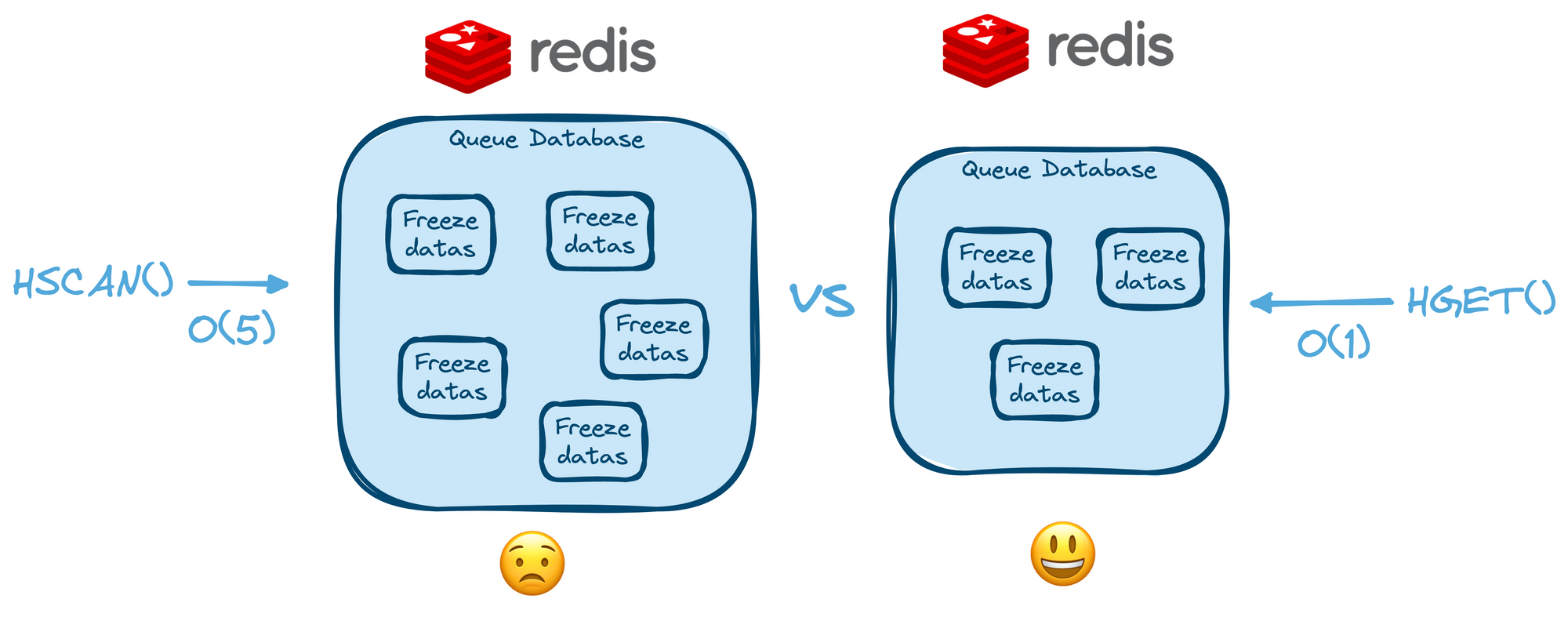
As explained, in the first implementation phase, we wanted to store data about every queue impacted by a freeze. This led us to think about the side-effect of this design decision in terms of storage. For example, how to loop over the data stored into Redis to handle the "freeze" pieces of information properly?
Looping over data in Redis can be a disaster in terms of performance. As we chose to use Redis hashes to store our data, we would have to use HSCAN to list every key, providing a time complexity of O(n). Plus, HSCAN can eventually block the server when processing big datasets, which can be dangerous performance-wise.
As explained earlier, we shifted the design to store only necessary information without thinking about the other queues impacted. By doing this, we could leverage HGET — which is way better performing in this situation, providing O(1) time complexity. This adds to all the pros of caring about the simplicity of use and process when it comes to databases and APIs.
We also wanted to use the most optimised tool to store and access our data in the fastest and lightest way possible. Our choice turned to the MessagePack library, which is perfectly fitted to work with Redis. MessagePack allows you to serialize and deserialize your data in a binary format. Even though it has some limitations on the data storage size, it is still more compact and way faster than JSON and fits perfectly well with the overall data size and types stored by our freeze feature. This allowed us to exploit the maximum of Redis, creating a data processing environment as performing as possible and also leaving space for future eventual scaling of our Redis database usage.
In conclusion, designing the freeze feature has confronted us with several healthy challenges that allowed us to apply essential principles of software development, conjugated with fundamental ergonomic and conceptual principles.
We are pleased to share our way of thinking with you, because in the end, freezing your queues has never been so fast and straightforward! 😉