Mastering Software Deployment Planning

Think about the last time your team pushed code to production. Was it a calm, controlled process, or a frantic, nail-biting scramble? The difference often comes down to one thing: planning.
Software deployment planning isn't just a fancy term for a checklist. It's the strategic roadmap that guides your new code from a developer's machine all the way to the live environment where your users are waiting. It’s the blueprint that turns a potentially chaotic event into a controlled, repeatable process.
What Is Software Deployment Planning Really?
Imagine trying to build a skyscraper. You wouldn't just show up with a pile of bricks and hope for the best, right? You'd need a detailed architectural plan to make sure the final building is sound, safe, and built to last. A deployment plan does the exact same thing for your software.
Without one, you’re essentially flying blind. You risk costly downtime, frustrated developers pulling all-nighters to fix unexpected breaks, and glaring security holes that only show up after launch. A solid plan completely flips that script.
From Chaos to Control
The whole point of deployment planning is to get rid of surprises. It forces your team to think through every dependency, every potential failure point, and every communication need long before anyone even thinks about hitting the "deploy" button. This proactive approach can transform a high-stress "go-live" moment into a complete non-event.
This kind of planning has never been more critical. Enterprise software spending is on track to hit $1.25 trillion globally by 2025, and an incredible 90% of new applications are expected to be cloud-native. This massive shift means deployment planning has to evolve, integrating modern DevOps and cloud strategies. You can dig deeper into software development statistics to see just how these trends are shaping our industry.
A great deployment plan isn’t just a document; it’s a shared understanding across teams. It ensures that everyone—from developers to operations—knows their role, the sequence of events, and what success actually looks like.
Every solid deployment plan is built on these foundational pillars, turning strategy into actionable steps.
The Core Components Of A Deployment Plan
| Component | What It Answers | Why It Matters |
|---|---|---|
| Scope & Goals | What are we deploying and why? | Sets clear expectations and defines success. |
| Timeline | When will each step happen? | Ensures all teams are synchronized and on schedule. |
| Resources | Who is doing what and with which tools? | Assigns clear ownership and prevents bottlenecks. |
| Risk Assessment | What could go wrong? | Identifies potential issues before they become emergencies. |
| Rollback Plan | How do we undo this if it fails? | Provides a safety net to minimize downtime and impact. |
| Communication | Who needs to know what and when? | Keeps stakeholders informed and avoids confusion. |
By addressing these core areas, you create a comprehensive guide that not only directs the deployment but also builds confidence and alignment across your entire organization.
The Real-World Benefits
A structured approach to software deployment planning pays off in ways that go far beyond a smooth launch day. It helps cultivate a more resilient, efficient, and collaborative engineering culture.
Here are the key advantages you'll see:
- Predictability and Reduced Risk: By spotting potential risks early, you can build out contingency and rollback plans. This drastically cuts down the odds of a catastrophic failure.
- Improved Efficiency: A clear plan minimizes wasted time and effort. Everyone knows what needs to be done and when, which smooths out the whole process.
- Enhanced Collaboration: The planning process itself is a powerful tool for bringing different teams together—Dev, QA, and Ops—fostering better communication and a shared sense of ownership.
- Higher Quality Releases: When deployments are meticulously planned, testing is more thorough and quality gates are respected. The result? A more stable and reliable product for your users.
The Seven Stages Of A Successful Deployment
A successful software deployment isn't a single, dramatic "go-live" event. It’s a structured journey, much like a conductor guiding an orchestra through a complex piece. Each stage has a clear purpose, building on the last to create a flawless release. Trying to skip a stage is like asking the percussion section to play without a tempo—the result is pure chaos.
This framework breaks the process down into a clear, seven-stage playbook. It's designed to turn what feels like a high-stakes gamble into a predictable, controlled operation.
Stage 1: Strategic Planning
This is where it all begins—defining what success actually looks like. Before anyone writes a single line of a deployment script, your team needs clear, measurable answers to some critical questions. What are the business goals for this release? What specific key performance indicators (KPIs) will tell us if we've hit the mark?
This phase is less about technology and more about alignment. Everyone, from product managers to operations engineers, has to be on the same page about the objectives. This shared understanding is what prevents scope creep and ensures every action you take is tied directly to a strategic outcome.
Stage 2: Environment Readiness
Once you know the "what" and "why," it's time to prepare the "where." This stage is all about setting up and validating your environments, particularly your staging and production servers. Are they identical? Do they have all the right dependencies, configurations, and access permissions?
Think of this as prepping a sterile operating room before surgery. Any difference between your testing ground (staging) and the live environment (production) can introduce dangerous, last-minute surprises. This is also when you double-check that your monitoring and alerting tools are configured and ready to keep a close eye on the deployment.
Stage 3: The Build Phase
With a solid plan and ready environments, it's finally time to create the artifact you'll actually deploy. During the build phase, your CI/CD pipeline kicks in, compiling the code, running unit and integration tests, and packaging everything into a stable release candidate.
This isn't just any build; it's the specific version that's been blessed for release. It must be versioned, immutable, and stored safely in an artifact repository. This guarantees that the exact same package that passes testing is the one that gets deployed, killing any "it worked on my machine" excuses.
Stage 4: The Pre-Production Gauntlet
Now the release candidate enters its final, most rigorous test in the staging environment. This is the gauntlet it has to run before it's ready to face real users.
- User Acceptance Testing (UAT): This is where key stakeholders and test users get their hands on the new features to confirm they work as expected and meet the business requirements.
- Performance Testing: Can it handle the heat? You simulate real-world traffic to see how the application holds up under load, ensuring it won’t slow to a crawl or crash during peak hours.
- Security Scanning: Automated tools scan the application for known vulnerabilities. You don't want to find out you've deployed a major security risk after the fact.
This infographic shows how a high-velocity team might structure its daily pipeline leading into this crucial stage.
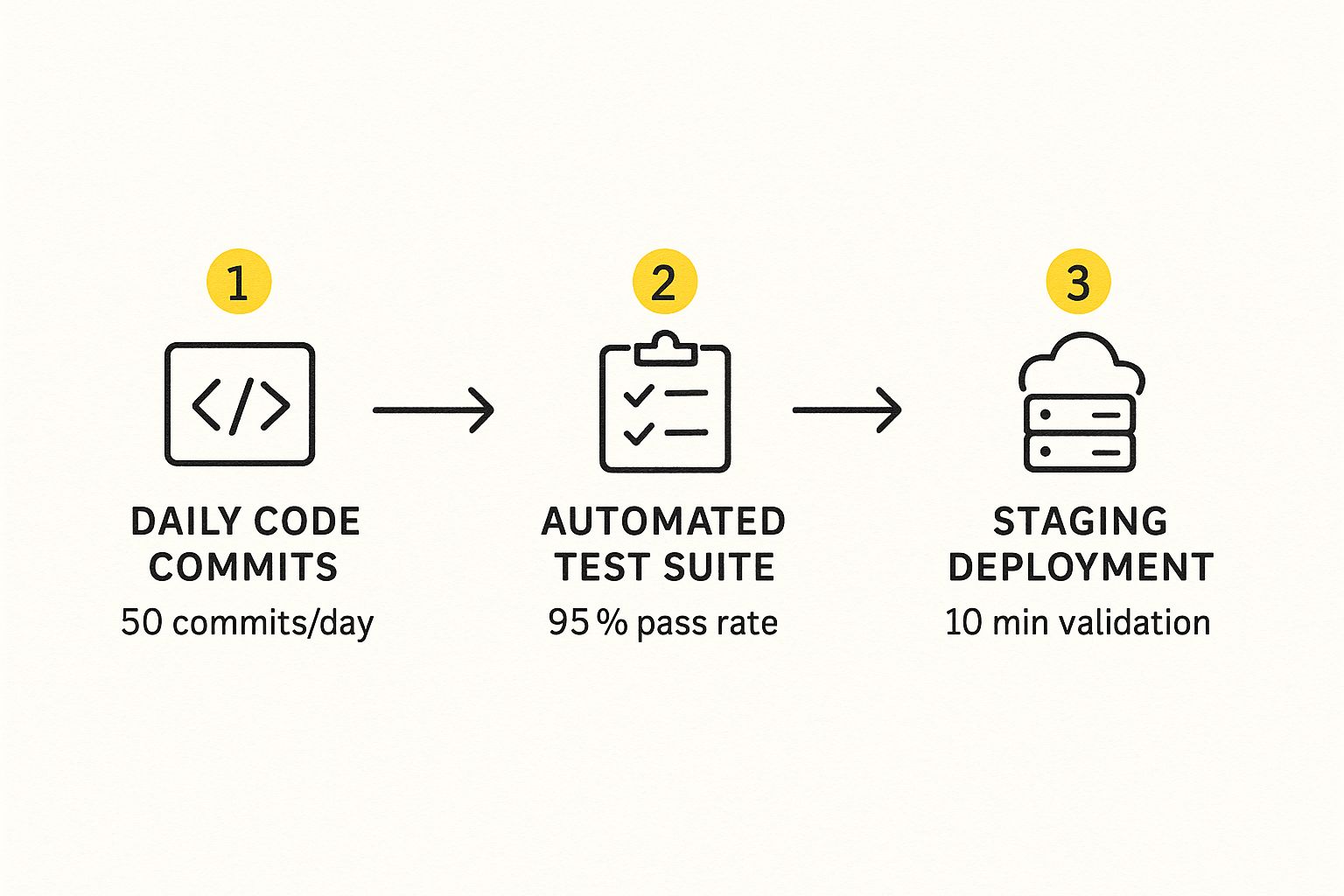
As the visual shows, the key is a rapid, automated feedback loop. A high volume of commits is balanced by a high test pass rate, which allows for quick and confident validation in the staging environment.
Stage 5: The Go-Live Moment
This is the main event. Using your chosen deployment strategy—like blue-green or canary—you execute the final rollout to the production environment. Your best friend here is a comprehensive checklist, ensuring every collaborator is identified, all stakeholders are notified, and end-users are prepared for the changes.
A critical part of this stage is having your rollback plan polished and ready to go at a moment's notice. You hope you won't need it, but you have to be prepared.
Stage 6: Post-Launch Vigilance
The deployment is live, but you can't relax just yet. Now begins a period of heightened monitoring. Your team needs to be glued to performance dashboards and log files, watching for any sign of trouble—a spike in error rates, increased latency, or any other unexpected behavior. This vigilance is what allows you to catch and fix issues before they have a major impact on your users.
Stage 7: The Debrief
Once the release has stabilized and the dust has settled, it's time for the final, and perhaps most important, stage: learning from the process. Hold a blameless post-mortem or retrospective. What went well? What went wrong? What can we do better next time?
This feedback loop is what separates a good team from a great one. It builds a culture of continuous improvement and helps you refine your deployment playbook over time. Mastering these steps is a core part of a mature engineering organization, and you can learn more about how it fits into the bigger picture by reading our guide on release management best practices.
Choosing Your Deрlоуment Strategy

How you push your code to production is just as important as what you're pushing. Picking the right strategy can be the difference between a smooth, uneventful update and a frantic, high-stakes scramble to fix a broken system.
Think of it like changing a tire on a car. You could try to lift the whole car at once—fast, maybe, but incredibly risky. Or you could lift one corner at a time, which is slower but far safer.
Choosing your approach is a core part of software deployment planning. It’s a game of trade-offs, balancing speed against risk, cost against user experience. No single strategy works for every project, so understanding the common playbooks is key to making the right call.
The All-Or-Nothing Big Bang Deployment
The Big Bang strategy is exactly what it sounds like: you take the old version offline, push the new one live, and bring it all back up. It’s the digital equivalent of flipping a giant switch.
On paper, this method is fast and simple. The reality? It’s also the riskiest. If a bug slips through, your entire application is down until you can either patch it on the fly or roll everything back. This approach really only makes sense for non-critical internal tools or apps where you can schedule a maintenance window and users expect downtime.
Slowly and Steadily With Rolling Deployments
A rolling deployment is a much more measured approach. Instead of updating everything in one go, you update a small subset of servers at a time. Once you’ve confirmed that batch is stable, you move to the next one, and so on, until the entire environment is running the new version.
This method drastically lowers your risk and avoids a total outage. If something goes wrong, it only impacts a fraction of your users, and you can hit the brakes on the rollout before it becomes a widespread problem. It’s a popular choice for good reason.
The Safety Net of Blue-Green Deployments
The Blue-Green deployment strategy takes safety to another level. The idea is to run two identical production environments side-by-side: "Blue" (the current live version) and "Green" (the new version). You deploy your new code to the inactive Green environment, where you can hammer it with tests without a single user noticing.
Once you’re confident Green is solid, you just flip a switch at the router level, redirecting all traffic from Blue to Green. The change is instant, resulting in zero downtime for your users.
The real magic of Blue-Green is the rollback plan. If you spot a problem after going live, you can switch traffic back to the original Blue environment in seconds. That immediate recovery gives you an incredible safety net.
Testing the Waters With Canary Deployments
If you want to be as cautious as possible, look no further than a Canary deployment. The name comes from the old "canary in a coal mine" practice, and it works the same way. You start by releasing the new version to a tiny slice of your user base—maybe just 1% or 5%. Everyone else continues using the old version, completely unaware.
This small group acts as your "canary." You monitor their experience and the application’s performance with extreme focus. If all systems are go, you gradually dial up the traffic to the new version until you hit 100%. If any issues pop up, you can quickly roll back the release for that tiny group with minimal disruption. It’s a fantastic way to test new features with real users without taking a huge risk.
Deployment Strategy Comparison Guide
Choosing between these strategies often comes down to your tolerance for risk, your budget, and how much downtime your users can stomach. To make it clearer, here’s a quick look at how these common strategies stack up against each other.
| Strategy | Downtime Impact | Risk Level | Cost/Resource Needs | Best For |
|---|---|---|---|---|
| Big Bang | High | Very High | Low | Non-critical systems, apps with maintenance windows. |
| Rolling | Low/None | Medium | Medium | General purpose, applications that need high availability. |
| Blue-Green | None | Low | High | Mission-critical apps where downtime is unacceptable. |
| Canary | None | Very Low | Medium | Validating risky new features with a subset of real users. |
Ultimately, there's no single "best" strategy—only the one that best fits your team's needs, your application's architecture, and your business goals. Understanding these trade-offs is the first step toward making deployments a routine, low-stress event.
The Modern Deployment Toolkit
A brilliant deployment strategy is only as good as the tools you use to bring it to life. In modern software development, it's a well-integrated toolkit that turns a detailed plan into a repeatable, automated reality. These tools don't just exist in a vacuum; they work together to create a seamless pipeline, moving code from a developer's keyboard to your users with both speed and reliability.
Think of it like a high-tech assembly line. Each station has a very specific job, and the entire process runs smoothly because every tool is designed to hand off its work to the next one automatically. This integration is what finally frees teams from manual grunt work and drastically cuts down the risk of human error.
Continuous Integration and Delivery Platforms
The engine of your deployment pipeline is your CI/CD platform. Tools like GitHub Actions, Jenkins, or GitLab CI/CD are the workhorses responsible for the foundational steps of any release. They automatically grab new code commits, build them into a usable package, and run a whole battery of automated tests to catch bugs before they ever see the light of day.
This constant cycle of building and testing gives developers immediate feedback. It ensures that every single piece of code merged into the main branch is already verified, creating a stable foundation for the final deployment. For any team that wants to ship frequently and reliably, a solid CI/CD setup is completely non-negotiable.
Infrastructure as Code
To deploy software consistently, the environment it runs in must also be consistent. This is where Infrastructure as Code (IaC) tools like Terraform or AWS CloudFormation come in. Instead of a developer manually clicking through a cloud console to set up servers, databases, and networks, IaC defines all of it in configuration files. You just run a script, and it builds the exact same environment, every single time.
This approach pays off in a few huge ways:
- Consistency: It eliminates "environment drift"—that sneaky process where staging and production slowly become different, leading to nasty deployment surprises.
- Speed: Spinning up or tearing down entire environments becomes a fast, automated process that takes minutes, not hours.
- Version Control: Your infrastructure is now versioned in Git just like your application code, giving you a crystal-clear history of every change.
Containerization and Orchestration
Okay, so you have a consistent environment. Now you need a consistent way to package and run your actual application. This is the job of containerization tools, and the most famous one is Docker. A container bundles your application code with all its dependencies—libraries, system tools, and settings—into a single, portable unit.
Containers finally solve the classic "it worked on my machine" problem. If it runs in a container on a developer's laptop, it will run exactly the same way in staging and production.
But what happens when you need to run hundreds or even thousands of these containers? That's where an orchestration platform like Kubernetes steps in. It manages the entire lifecycle of your containers, handling things like scaling, networking, and self-healing to make sure your application is always available and performs well under pressure.
Monitoring and Observability Tools
The final piece of the puzzle is all about visibility. Once your application is live, you need to know how it's actually doing. Monitoring tools like Prometheus or Datadog collect a constant stream of metrics, logs, and traces from your live application.
They watch for error spikes, high latency, or unusual resource usage, alerting your team to potential problems—often before they impact a large number of users. This immediate feedback loop is critical for both verifying that a deployment was successful and quickly diagnosing any issues that pop up after launch.
Automating Your Deployment With Mergify
All the planning, strategies, and toolkits we've talked about are the bedrock of a successful release. But the real magic happens when you bring those concepts to life with an automated workflow—one that executes your plan perfectly, every single time. This is where theory meets practice. You move from manual checklists to an intelligent, self-managing pipeline.
A modern software deployment plan shouldn't mean developers have to babysit pull requests (PRs) or manually tick boxes to see if a change is ready for the next stage. The real goal is to build the plan into your process. This is exactly where a tool like Mergify becomes so valuable, acting as an automation engine right inside your GitHub repository.
From Manual Checks to Automated Gates
Instead of a senior engineer sinking hours into reviewing PRs just to confirm they meet basic deployment criteria, Mergify can handle the heavy lifting. You define a set of rules in a simple mergify.yml file, which then acts as your automated quality gatekeeper.
These rules enforce all the critical pre-deployment checks, making sure no PR gets a green light until it satisfies every condition you’ve set.
- Passing CI Checks: Automatically verify that all continuous integration tests and builds are green.
- Required Approvals: Ensure the PR has the right number of reviews from the right teams (e.g., one from QA, one from security).
- Code Coverage Standards: Block any change that would drop your overall test coverage below a set threshold.
- Label Verification: Confirm that the PR is correctly labeled (like
ready-to-deployorbugfix) before it moves forward.
This kind of automation turns your deployment plan from a static document into a living, enforceable set of rules. It slashes human error and frees up your most experienced developers to solve bigger problems. This approach is a cornerstone of modern development, which you can read more about in our guide to CI/CD best practices.
Protecting Your Main Branch With a Merge Queue
One of the biggest risks in any deployment pipeline is an unstable main branch. When multiple PRs are merged in quick succession, a change that passed tests in isolation can blow up when combined with something else. The result? A broken main branch, which brings all deployments to a screeching halt.
Mergify’s merge queue solves this by creating a safe, orderly process for merging code. Instead of merging PRs directly, they’re added to a queue for validation.
Think of a merge queue as an airlock for your main branch. It takes each "ready" pull request, updates it with the latest version of main, re-runs all CI checks on the combined code, and only then merges it. If any check fails, the problematic PR is kicked out of the queue without ever touching—or breaking—your production branch.This screenshot shows Mergify's merge queue in action, processing pull requests sequentially to guarantee stability.
The visual here highlights a huge benefit: PRs are tested together before merging, which catches the kind of integration bugs that individual CI runs always miss. This gives you a perpetually green main branch, making every single commit a safe and viable release candidate.
Automating Complex Workflows Like Backporting
Your deployment plan doesn't just end when a feature hits production. What happens when a critical bug is fixed in main but also needs to be applied to older, supported versions of your software? This process, called backporting, is often a tedious and error-prone manual job.
With Mergify, you can automate this entire workflow. A simple rule can detect when a PR with a bugfix label is merged to main, and then automatically create a new PR with that same fix, but targeted at your v2.1-maintenance branch.
This ensures critical fixes get to all your users without a developer having to manually copy-paste code between branches, saving a ton of time and preventing costly mistakes.
Essential Practices For Flawless Deployments
A great deployment plan is built on repeatable, disciplined habits. It’s the consistent application of these core practices that separates a smooth, predictable release from a chaotic, high-stress emergency. When your team adopts these habits, you don’t just deploy code; you build confidence.
Think of them like a pilot's pre-flight checklist. Each item is non-negotiable because skipping even one can introduce unacceptable risk and jeopardize the entire mission.
Create A Bulletproof Rollback Plan
This is the big one. The single most important practice is knowing exactly how to undo a deployment before you even start it. A rollback plan is your safety net. This isn't about expecting failure; it's about being thoroughly prepared for it. Your plan needs to be detailed, tested, and as automated as possible so you can revert to a stable state in minutes, not hours.
Your plan should clearly answer a few critical questions:
- What's the trigger for a rollback? (e.g., error rate jumps by 2%)
- Who has the final authority to make the call?
- What are the exact technical steps needed to revert the changes?
Implement Meaningful Monitoring
Once your code is out in the wild, you need to see what it's doing. But effective monitoring isn’t about drowning yourself in data—it’s about tracking the right signals. Zero in on the key performance indicators (KPIs) that tell you about both system health (like latency and error rates) and what your users are actually experiencing. Then, set up smart alerts that flag real problems, not just random noise.
A classic mistake is having thousands of metrics but no real insight. Your goal should be observability—the power to ask new questions of your system without having to deploy new code. That's what lets you diagnose unexpected issues the moment they appear.
Maintain Documentation People Actually Use
Documentation often feels like the first thing to go when things get busy, but it's essential if you want to scale successfully. Your deployment plans, checklists, and post-mortem notes need a home—a central, easy-to-find place. The best documentation is short, actionable, and treated like a living document that gets updated after every single release. This discipline is foundational to many of the benefits of continuous integration you can explore further.
Run Blameless Post-Mortems
Things will go wrong. They inevitably do. When they do, the goal isn't to find someone to blame; it's to find the systemic cause and make sure it never happens again. A blameless post-mortem creates a psychologically safe space where engineers can talk openly about what happened without fearing blame or punishment.
This cultural shift fosters a powerful sense of shared ownership and is the engine for continuous improvement. The only output that matters is a set of actionable fixes to your process or tools. By embedding these practices, you transform your entire approach to software deployment, making every release more reliable than the last.
Common Questions, Answered
Even with the best-laid plans, a few tricky questions always pop up when the rubber meets the road. Let's tackle some of the most common hurdles teams face when putting their deployment strategy into practice.
How Do You Handle Database Migrations?
Database migrations are easily one of the most nerve-wracking parts of any deployment. One wrong move, and you could compromise your data. The secret is to stop treating schema migrations and application deployments as a single event.
A solid best practice is to make your database changes backward-compatible. This means the new version of your application can work with the old database schema, and vice-versa. For instance, if you need to add a new column, don't make it NOT NULL right away. Add it as a nullable column first. This simple step allows both old and new codebases to run without throwing errors.
Once the new application code is deployed and stable, you can circle back. Run a separate script to populate the new column for existing records, and only then, in a future release, make it non-nullable.
Think of database changes like their own mini-releases. They need to be managed, tested, and have a rollback plan ready to go, just in case something goes sideways.
What’s the First Step for a New Team?
If your team is starting from scratch with no formal plan, the first step isn't to build a perfect, all-encompassing strategy. It's much simpler: document your current process.
Seriously. Just write down exactly what you do right now to get code from a developer's machine to production, even if it feels messy or chaotic.
This document becomes your baseline—your "you are here" map. It will immediately shine a light on the biggest pain points and give you a concrete starting point. From there, you can introduce two of the most impactful elements: a simple deployment checklist and a documented rollback plan.
How Do You Get Management Buy-In?
Getting leadership on board means speaking their language. "We need better deployment tools" is a technical problem. "We're losing money and exposing the business to risk" is a business problem. See the difference?
Frame your proposal around tangible business outcomes. Arm yourself with data on:
- Downtime Costs: Put a dollar amount on past outages. How much revenue was lost? How many support tickets were generated?
- Developer Hours Wasted: Track the time your team sinks into manual deployment tasks and cleaning up post-release fires. That’s expensive time that could be spent building features.
- Business Risk: Connect flawed releases to real-world consequences, like security holes or frustrated customers who might churn.
When you show how a solid deployment plan isn't a cost but an investment that reduces risk and saves money, it becomes a much easier conversation to have.
Ready to turn your deployment plan into an automated, error-free reality? Mergify's merge queue and automation engine enforce your quality gates directly within GitHub, protecting your main branch and eliminating manual drudgery. See how it works.